









 texto em
texto em  Inglês (pdf)
Inglês (pdf)
 Artigo em XML
Artigo em XML
 Enviar este artigo por email
Enviar este artigo por email
 Permalink
Permalink
1 Introdução
O desenvolvimento de habilidades básicas de ouvinte e falante é crítico para que o indivíduo adquira independência em suas interações com o mundo, uma vez que estas são cruciais para a aquisição de repertórios mais complexos, como habilidades sociais, leitura com compreensão e solução de problemas (Greer & Ross, 2008; Greer & Speckman, 2009). A integração das habilidades de falante e ouvinte resulta em um operante de ordem superior denominado “nomeação” (naming - Horne & Lowe, 1996; mais recentemente caracterizado como nomeação bidirecional - bidirectional naming - BiN - Miguel, 2016). De acordo com Horne e Lowe (1996), a BiN é uma relação comportamental que combina os comportamentos de falante e ouvinte em um mesmo indivíduo, de forma que a presença de um pressupõe a presença do outro. Isso implica que, ao adquirir uma nova resposta de ouvinte por meio de treino direto, o indivíduo adquire simultaneamente a resposta de tato (operante verbal controlado por antecedente não verbal e mantido por reforço social - Skinner, 1992) em relação ao mesmo estímulo, e vice-versa.
Segundo Horne e Lowe (1996), a aquisição da BiN dá-se a partir de interações cotidianas da criança com seus cuidadores e outras pessoas de seu ambiente, nas quais a criança aprende, inicialmente, de maneira independente um do outro, repertórios de ouvinte, ecoico (operante verbal controlado por antecedente verbal, com correspondência ponto-a-ponto entre antecedente e resposta, ambos na modalidade vocal - Skinner, 1992) e tato. Quando esses três repertórios se integram, temos a emergência da BiN como um operante de ordem superior. A partir disso, de acordo com Horne e Lowe (1996), dicas contextuais fornecidas pelos cuidadores, como apontar para um objeto ou falar seu nome na presença deste, serão suficientes para evocar todos os componentes verbais da BiN.
Greer e Ross (2008) denominaram esse fenômeno de “nomeação completa” (full naming), quando o indivíduo é capaz de aprender tatos puros (tendo como antecedente apenas um estímulo não verbal) ou impuros (tendo como antecedentes estímulos verbais e não verbais - Skinner, 1992) e respostas de ouvinte após apenas observar outra pessoa tatear um estímulo na presença deste, sem necessidade de treino direto ou reforçamento dessas respostas, possibilitando a aquisição de repertórios verbais de maneira incidental no ambiente natural (Greer & Longano, 2010; Greer & Ross, 2008; Greer & Speckman, 2009).
No entanto, as experiências em ambiente natural podem não ser suficientes para o desenvolvimento de repertórios verbais, entre eles a BiN, em pessoas com Transtorno do Espectro Autista (TEA) e outros distúrbios do desenvolvimento, sendo necessário procedimentos de ensino mais estruturados (Olaff, Ona, & Holth, 2017; Smith, 2001). Greer e colaboradores desenvolveram um procedimento para estabelecimento de BiN em pessoas que não a desenvolvem de maneira natural: o procedimento de Instrução com Múltiplos Exemplares (Multiple Exemplar Instruction - MEI). O MEI implica “colocar respostas [...] inicialmente independentes sob controle conjunto de estímulos. Isso é feito rotacionando diferentes respostas a um mesmo estímulo [...] de forma que os alunos adquiram a capacidade de aprender múltiplas respostas a partir da instrução de apenas uma [...]” (Greer & Ross, 2008, p. 296).
Vários estudos investigaram a eficácia do MEI para induzir a BiN em crianças com desenvolvimento típico (Gilic & Greer, 2011) e atípico (Fiorile & Greer, 2007; Greer, Stolfi, Chavez-Brown, & Rivera-Valdes, 2005; Greer, Stolfi, & Pistoljevic, 2007; Hawkins, Kingsdorf, Charnock, Szabo, & Gautreaux, 2009; Olaff, Ona, & Holth, 2017; Santos & Souza, 2016). Esses estudos têm demonstrado que o procedimento de MEI tem sido eficaz em produzir a emergência de BiN na maioria dos participantes após uma a três exposições ao treino de MEI.
Embora, de forma geral, o MEI se mostre eficaz para o estabelecimento dos repertórios de ouvinte, tato e de BiN, ele se caracteriza por ser um procedimento que demanda um longo processo de ensino. Na busca por procedimentos mais eficientes e que se aproximem mais das condições naturais de aquisição da linguagem, nos últimos anos, alguns pesquisadores vêm avaliando a eficácia do procedimento de observação de pareamento de estímulos (Stimuli Pairing Observation Procedure - SPOP) para induzir repertórios de ouvinte, tato e de BiN, em pessoas com desenvolvimento típico (Carnerero & Pérez-González, 2015; Rosales, Rehfeldt, & Huffman, 2012) e atípico (Byrne, Rehfeldt, & Aguirre, 2014; Carnerero & Pérez-González, 2014; Vallinger-Brown & Rosales, 2014). O SPOP consiste no pareamento de dois estímulos, sem que nenhuma resposta seja exigida do indivíduo, além da observação desse pareamento, com posterior avaliação da emergência de relações entre esses estímulos. Por exemplo, um estímulo visual (objeto ou figura) é nomeado (estímulo auditivo) algumas vezes (n pareamentos) diante de um indivíduo, e, posteriormente, é avaliado se o indivíduo aprendeu respostas de tato e ouvinte para aquele objeto-figura (Byrne, Rehfeldt, & Aguirre, 2014; Carnerero & Pérez-González, 2014; Rosales, Rehfeldt, & Huffman, 2012).
Em um estudo realizado com quatro crianças e adolescentes com diagnóstico de TEA, Carnerero e Pérez-González (2014) avaliaram se respostas de tato e seleção de figuras emergiriam após o procedimento de observação do pareamento da figura com seu nome e, além disso, testaram se a BiN poderia ser induzida em crianças que não o apresentavam, por meio do SPOP. Todos os participantes demonstraram emergência dos repertórios de tato e seleção de figuras após terem sido expostos a ciclos de pareamentos e sondas de tato, indicando que o SPOP foi eficaz para produzir repertório de BiN em pessoas com autismo.
Byrne, Rehfeldt e Aguirre (2014) também realizaram um estudo com o objetivo de avaliar a efetividade do procedimento de SPOP na emergência de respostas de tato e ouvinte para crianças com TEA. Os resultados mostraram que, embora as exposições múltiplas às sessões de SPOP tenham produzido um aumento nas respostas de tato e ouvinte dos três participantes, somente um participante atingiu critério de aprendizagem para tato e ouvinte com o conjunto original de estímulos. Esse resultado sugeriu que o SPOP podia não ser eficiente para produzir os dois componentes da BiN.
Um aspecto que merece ser destacado nos estudos de Carnerero e Pérez-González (2014) e de Byrne, Rehfeldt e Aguirre (2014) é o repertório inicial dos participantes. Enquanto que em Carnerero e Pérez-González (2014) os participantes já apresentavam um repertório amplo de tato e ouvinte, e três deles apresentavam, inclusive, habilidades básicas de BiN, os participantes de Byrne, Rehfeldt e Aguirre (2014) estavam avaliados no nível 1 do Verbal Behavior Milestones Assessment and Placement Program (VB-MAPP - Sundberg, 2014), pois tinham habilidades de tato e ouvinte em um nível básico e seus repertórios eram restritos a respostas de tato e ouvinte que haviam sido ensinadas por meio de treino direto. Essa diferença entre os repertórios iniciais dos participantes pode ter influenciado nos resultados obtidos.
Longano e Greer (2015) utilizaram um procedimento para induzir a BiN em crianças com e sem diagnóstico de TEA semelhante ao SPOP. Eram apresentados ciclos de pareamentos entre estímulos auditivos e visuais, seguidos de sondas de tato até que o participante atingisse critério de aprendizagem, e, posteriormente, a BiN era testada com novos conjuntos de estímulos. A diferença é que os estímulos utilizados nos pareamentos foram previamente condicionados com reforçadores. Nesse estudo, todos os participantes apresentaram nomeação completa após terem sido expostos ao SPOP com, pelo menos, dois conjuntos de estímulos.
Observa-se, então, que, enquanto o MEI é um procedimento que já foi testado por diversos estudos que comprovaram sua eficácia na produção dos dois componentes da BiN em pessoas com TEA ou com atraso no desenvolvimento, o SPOP é uma alternativa que ainda possui poucos estudos que testaram e comprovaram sua eficácia na produção de comportamento de falante e ouvinte nessa mesma população. No entanto, o SPOP tem como vantagem o fato de aproximar-se mais do modo como as crianças adquirem repertório de falante e ouvinte no ambiente natural, aproximando o contexto de ensino das contingências naturais da vida do indivíduo (Carnerero & Pérez-González, 2014; Byrne, Rehfeldt, & Aguirre, 2014). O SPOP, se for eficaz, pode ser, portanto, uma alternativa para o estabelecimento de BiN, com menor grau de complexidade de aplicação e menor demanda discriminativa para os indivíduos, uma vez que a única resposta exigida é a observação dos pareamentos.
Os estudos já realizados mostram que ambos os procedimentos podem produzir resultados positivos no que diz respeito ao ensino de tatos e respostas de ouvinte para pessoas com TEA, embora existam evidências mais consistentes sobre a eficácia do MEI. No entanto, não foram encontrados estudos que comparem os dois procedimentos em relação à sua eficiência nesse tipo de ensino. Outras variáveis, além da eficácia, devem ser consideradas na avaliação da eficiência de um procedimento de ensino, como o tempo necessário para que o indivíduo comece a apresentar os repertórios alvos da intervenção, bem como a generalização desses repertórios. Dessa forma, o presente estudo teve como objetivo comparar a eficiência do MEI e do SPOP na produção de BiN, considerando o número de sessões necessárias para que o participante atinja critério de aprendizagem e a generalização dos comportamentos adquiridos com cada procedimento.
2 Método
Nesta seção, caracterizamos os participantes da pesquisa, o ambiente em que se deu a coleta e os materiais utilizados, o conjunto de estímulos utilizados, o delineamento experimental e as etapas para o procedimento de coleta de dados, o registro e a análise de dados e, por fim, a concordância entre observadores e integridade do procedimento.
2.1 Participantes
Participaram deste estudo quatro meninos com diagnóstico de Transtorno do Espectro Autista (TEA): P1, P3 e P4, com 5 anos, e P2, com 9 anos. Antes do início do estudo, o repertório verbal de cada participante foi avaliado utilizando o VB-MAPP (Sundberg, 2014). Todos apresentaram desempenhos compatíveis com o Nível 1 do VB-MAPP nos domínios de tato, resposta de ouvinte e habilidades de percepção visual e emparelhamento ao modelo (P1 - alcançou 29 pontos de 45 possíveis, P2 - 25,5, P3 - 25 e P4 - 25,5). Os participantes apresentavam repertório de ecoico de palavras ou frases curtas, ainda que com algumas dificuldades de pronúncia. Nenhum dos participantes apresentava BiN, conforme foi avaliado na sonda inicial desse repertório. Todos os participantes eram atendidos pelo serviço especializado ao TEA no Centro Especializado de Reabilitação e Promoção de Saúde do governo do Maranhão (CER-MA), Brasil, com frequência de cinco vezes por semana e sessões com duração de uma hora e meia, onde recebiam intervenção baseada na Análise do Comportamento Aplicada.
Os responsáveis legais dos participantes assinaram um Termo de Consentimento Livre e Esclarecido autorizando a participação no estudo. O estudo foi aprovado pelo comitê de ética em pesquisa do Núcleo de Medicina Tropical da Universidade Federal do Pará - UFPA (Parecer 2.749.780).
2.2 Ambiente e materiais
A pesquisa foi realizada nas instalações do CER-MA, em uma sala de atendimento individualizado ou em um espaço reservado em uma sala utilizada para atendimento em grupo em momentos que não estivessem ocorrendo atividades. Para o registro e coleta de dados, foram utilizados lápis, folhas de registro elaboradas especificamente para o estudo e uma câmera de vídeo digital. Para apresentação das tarefas, foram utilizados bonecos e estímulos identificados como potencialmente reforçadores para as crianças conforme descrito a seguir.
2.3 Estímulos
Estímulos experimentais: foram utilizados cinco conjuntos de estímulos (C1, C2, C3, C4, C5), cada um com três estímulos, que consistiram em bonecos de formato antropomórfico (variando entre 10 e 30 cm de altura), desconhecidos pelos participantes. Cada conjunto de estímulos foi utilizado em etapas diferentes do procedimento, conforme descrito no Procedimento. Os nomes dos estímulos foram palavras dissílabas (ex: BIPE, MAKE, DEDE), construídas a partir de sílabas simples que os participantes fossem capazes de pronunciar (o que foi avaliado na primeira etapa do Procedimento).
Estímulos consequenciadores: foi feito um levantamento de possíveis reforçadores com base nas indicações dos cuidadores e terapeutas que já atendiam às crianças. Durante as sessões, várias opções de possíveis estímulos reforçadores ficavam disponíveis para que a criança pudesse ter acesso nos momentos de intervalo ou entre tentativas de ensino. Além disso, houve consequências na forma de elogios e aprovação.
2.4 Delineamento experimental
Foi utilizado um delineamento de sujeito único de linha de base múltipla com técnica de sondas múltiplas entre participantes (Horner & Baer, 1978). Neste estudo, o delineamento de linha de base múltipla foi aplicado entre pares de participantes (P1 e P2; P3 e P4). A ordem de aplicação dos dois tratamentos experimentais testados nesse estudo (MEI e SPOP) variou entre os participantes de cada par. Para os participantes P1 e P3, foi aplicado, inicialmente, o tratamento MEI e, posteriormente, o SPOP. Já, para os participantes P2 e P4, a ordem de aplicação dos tratamentos foi inversa. Dessa forma, foi possível avaliar o efeito isolado de cada um dos tratamentos e também o efeito da sua ordem de aplicação, além de replicá-los entre dois participantes.
2.5 Procedimento
O estudo foi desenvolvido em nove etapas apresentadas na Figura 1, de maneira geral, e descritas de forma mais detalhada à continuação. Todos os participantes passaram por todas as etapas do procedimento, porém o momento de início da linha de base e implementação do primeiro tratamento experimental (Etapas 4 e 5) variou em função do delineamento de linha de base múltipla com técnica de sondas múltiplas. Inicialmente, todos participantes passaram pelas etapas 1 a 3. Posteriormente, foi medida a linha de base dos participantes P1 e P3, seguida da implementação das demais etapas do procedimento descritas anteriormente. Quando os participantes P1 e P3 atingiram critério no primeiro tratamento experimental implementado, os participantes P2 e P4 passaram por outra sonda de BiN, seguida da linha de base e das demais Etapas do procedimento.
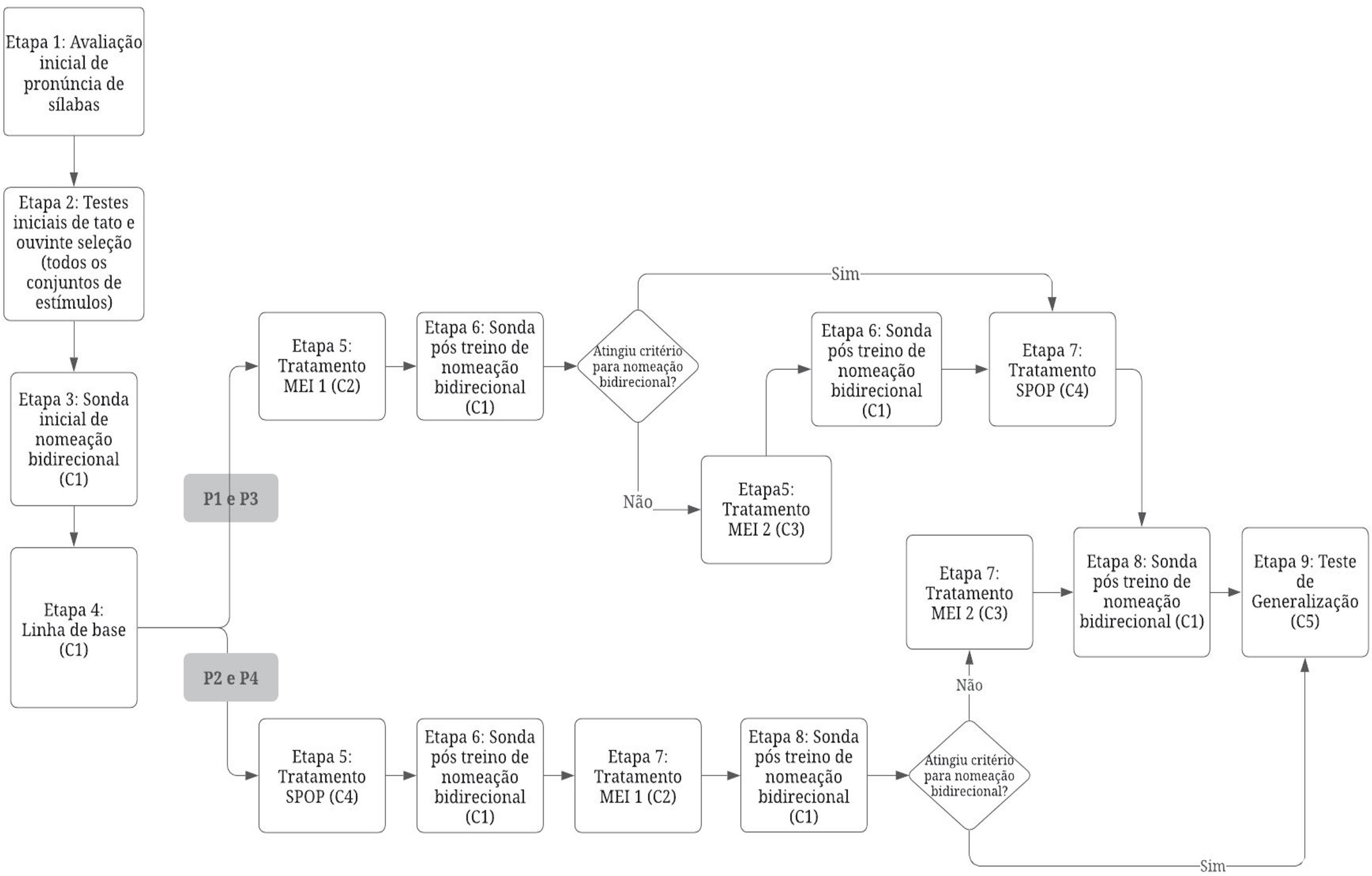
Avaliação inicial da pronúncia de sílabas (Etapa 1): essa etapa teve como objetivo selecionar um conjunto de sílabas que todos os participantes fossem capazes de pronunciar corretamente para compor os nomes dos estímulos. A avaliação foi feita com base na observação de palavras vocalizadas pelas crianças durante o atendimento compostas pelas sílabas avaliadas ou em tentativas de ecoico, nas quais o experimentador solicitava que a criança repetisse a sílaba falada por ele (p. e. “repita BA”), sem consequenciação para acerto ou erro. Foram realizadas de uma a duas sessões de avaliação para cada criança, até que foram identificadas 23 sílabas que todos os participantes pronunciavam corretamente.
Testes iniciais de tato e ouvinte seleção (Etapa 2): o objetivo dessa etapa foi verificar se os estímulos que foram utilizados no estudo eram de fato desconhecidos pelos participantes. Qualquer estímulo ao qual o participante respondesse corretamente em tentativas de ouvinte mais que uma vez e em tentativas de tato pelo menos uma vez seria substituído. Também foram excluídos estímulos que o participante nomeasse mais de uma vez com o mesmo nome, ainda que este não fosse o nome atribuído pelo experimentador.
Nessa etapa era realizado um bloco (composto por nove tentativas, três para cada estímulo) de tato e um bloco de ouvinte seleção, para cada conjunto de estímulos que foi utilizado no estudo. As tentativas de tato consistiram na apresentação de um estímulo para o participante (a experimentadora segurava o estímulo na frente do participante), seguida da pergunta “Quem é?” ou “Qual o nome dele?”. A ordem de apresentação dos estímulos era randomizada pela experimentadora no momento da aplicação. Uma reposta era considerada correta quando o participante dizia o nome do estímulo pronunciado corretamente. Se o participante emitisse uma resposta vocal não correspondente ao nome do estímulo, ou não respondesse em até 5 segundos, a resposta era considerada incorreta. Para o participante P4, as tentativas de teste de tato consistiram somente na apresentação do estímulo, sem nenhuma instrução, o que foi feito para evitar que o participante apenas repetisse a instrução dada pelo terapeuta, uma vez que esse era seu padrão comportamental frequente.
As tentativas de ouvinte consistiram na apresentação de três estímulos sobre a mesa em frente ao participante, seguida da instrução “Me mostre (nome do estímulo)”. Tanto a ordem de apresentação dos estímulos modelo quanto a posição dos estímulos comparação apresentados na mesa eram randomizados pela experimentadora a cada tentativa. Uma resposta era considerada correta se o participante apontasse, tocasse ou pegasse o estímulo nomeado pelo experimentador. Qualquer resposta diferente disso ou se o participante não respondesse em até 5 segundos, era considerado erro. Respostas corretas ou erradas eram seguidas por um intervalo entre tentativas de aproximadamente três segundos. Os testes de tato foram sempre realizados antes dos testes de ouvinte para garantir que o fato de o participante escutar os nomes dos estímulos nas tentativas de ouvinte não interferisse em seu desempenho nos testes tato.
Sondas de BiN com Conjunto C1 (Etapas 3, 6 e 8): a sonda foi baseada no teste de BiN proposto por Greer e Ross (2008). Inicialmente foi realizado o treino de emparelhamento ao modelo por identidade (Identity Matching to Sample - IDMTS) com o participante, com tato do estímulo modelo pelo experimentador. O treino era realizado em blocos de nove tentativas (três por estímulo) por sessão. A tarefa consistia na apresentação de um estímulo modelo, enquanto o experimentador dizia seu nome na instrução dada, por exemplo: “Coloque junto (nome do estímulo)”. Ao mesmo tempo, eram apresentados três estímulos comparação, entre os quais estava um idêntico ao modelo. A resposta correta consistia em colocar o estímulo modelo sobreposto ao estímulo comparação correspondente ou selecionar o estímulo correspondente entre os três estímulos comparação. Respostas corretas eram seguidas de elogios e aprovação e/ou estímulos reforçadores tangíveis. Ao consequenciar respostas corretas, a experimentadora dizia novamente o nome do estímulo modelo, por exemplo: “Muito bem! Esse é o (nome do estímulo)”. Dessa forma, o participante tinha oportunidade de ouvir o nome de cada estímulo na presença deste, seis vezes em cada bloco de IDMTS.
Esse treino era realizado até que o participante atingisse o critério de duas sessões com 89% de acertos ou de uma com 100%. Após o participante atingir critério de aprendizagem na tarefa de IDMTS, eram realizadas sondas de tato e ouvinte seleção, idênticas aos testes iniciais desses repertórios (somente com C1). Era considerada uma demonstração do repertório de BiN desempenhos acima de 78% de respostas corretas em cada repertório testado, não podendo o participante cometer mais de um erro por estímulo. Participantes que tiveram um desempenho inferior a este, foram expostos à Etapa 4 do estudo (linha de base).
Linha de base (Etapa 4): consistiu na realização de, no mínimo, três sessões de testes de tato e ouvinte seleção (idênticos aos testes iniciais) com os estímulos de C1, até que o participante demonstrasse estabilidade no desempenho dos dois repertórios ou uma tendência decrescente.
Tratamento MEI (Etapa 5 ou 7): esse tratamento experimental consistiu no treino dos repertórios de IDMTS com tato do estímulo modelo pelo experimentador, ouvinte seleção e tato, com C2 e C3. A ordem dos operantes solicitados em cada tentativa era randomizada, assim como os estímulos apresentados, por exemplo, uma sequência de três tentativas poderia ser: IDMTS com o estímulo CADU, tato com o estímulo BOBI e ouvinte com PEPE.
O treino de IDMTS era idêntico ao realizado na etapa de sonda inicial de BiN. As tentativas de ouvinte seleção e tato eram conforme descrito na etapa de testes iniciais desses repertórios, com a diferença de que tentativas corretas eram reforçadas, enquanto tentativas incorretas ou omissões de resposta por mais de 5 segundos eram seguidas de procedimento de correção, que consistiu na reapresentação da instrução e ajuda para realizar a tarefa (ajuda física ou gestual para tentativas de ouvinte e ajuda modelo vocal para tentativas de tato), seguida de um feedback verbal menos entusiástico (apenas a confirmação de que o participante havia acertado, por exemplo: “isso, esse é BOBI”) do que o fornecido em tentativas em que o participante respondia corretamente. Além disso, durante os treinos, foram utilizados alguns tipos de ajuda para facilitar a emissão de respostas corretas pelo participante, principalmente no início do treino. Nos treinos de tato, foram utilizadas ajuda modelo vocal imediata e atrasada (o experimentador esperava em média 3 segundos após a instrução, caso o participante não respondesse, era dada a ajuda), e nos treinos de ouvinte, ajuda gestual imediata e atrasada. As dicas iam sendo retiradas de acordo com desempenho dos participantes nas tentativas anteriores. Nos casos em que os participantes desviavam o olhar no momento ou logo após a apresentação dos estímulos, respondiam selecionando dois estímulos simultaneamente ou em sequência, ou apresentavam comportamento de resistência para cumprir a tarefa, a tentativa era desconsiderada e reapresentada.
As sessões foram compostas de nove tentativas (três por estímulo) para cada repertório, totalizando 27 tentativas. Estas foram divididas em blocos menores de tentativas (geralmente três blocos de nove tentativas, mas variando de acordo com o nível de tolerância da criança), entre os quais a criança tinha um intervalo de 2 a 5 minutos no qual tinha acesso a itens reforçadores.
O critério de aprendizagem para esse tratamento foi de 89% de respostas corretas em cada repertório por duas sessões consecutivas ou uma com 100%, para cada repertório. O critério de interrupção do tratamento foi de 12 sessões sem que a criança conseguisse atingir o critério de aprendizagem.
Após o participante atingir um dos dois critérios acima com o primeiro conjunto de treino do tratamento MEI (C2), era realizada uma sonda de BiN com C1. Caso o participante não apresentasse a BiN, conforme critério definido neste estudo (78% de resposta corretas em ambos os repertórios, não podendo apresentar mais de um erro por estímulo), era realizado um segundo treino de MEI com um novo conjunto de estímulos (C3), e, após atingir critério de aprendizagem ou de interrupção do tratamento, era exposto a uma nova sonda de BiN com C1.
Tratamento SPOP (Etapa 5 ou 7): Esse tratamento foi realizado com C4. Cada sessão de SPOP teve um número total de 27 pareamentos auditivo-visuais, de forma que o número de pareamentos foi equiparado com a quantidade de tentativas em uma sessão de MEI. Esses pareamentos consistiram na apresentação de um estímulo seguido de seu nome ditado pelo experimentador, após este ter garantido a atenção da criança para o estímulo apresentado. Não foram exigidas respostas de tato ou de ouvinte seleção da criança. Os pareamentos eram feitos em um contexto de brincadeira, no qual o experimentador interagia com a criança utilizando os estímulos (bonecos) de diferentes formas que pudessem ser interessantes para a criança e favorecessem o direcionamento da sua atenção para os estímulos alvo. Caso respostas espontâneas de tato ou ouvinte seleção ocorressem durante a interação, estas não eram reforçadas diferencialmente. Caso o experimentador apresentasse o estímulo auditivo, mas notasse que o participante não estava olhando para o estímulo visual naquele momento, o pareamento era reapresentado.
Os pareamentos eram divididos em blocos (geralmente de nove pareamentos, três por estímulo, mas podendo variar de acordo com interesse momentâneo da criança pelos estímulos), apresentados de maneira randômica e/ou seguindo o interesse dos participantes pelos estímulos. Ao final de cada bloco, o participante tinha um intervalo de 2 a 5 minutos, no qual tinha acesso a itens reforçadores e podia brincar livremente.
Após o terceiro intervalo, o participante passava por sondas de tato e ouvinte seleção com os estímulos do conjunto C4, idênticas aos testes iniciais desses repertórios. O critério de aprendizagem nesse tratamento foi de 89% de respostas corretas nas sondas de tato e ouvinte (para cada repertório) em duas sessões consecutivas ou 100% em uma, e o critério de interrupção do tratamento foi o mesmo adotado para o MEI. Após atingir critério de aprendizagem, o participante seguia para uma nova sonda de nomeação com C1.
Teste de generalização (Etapa 9): Foi idêntico à sonda inicial de BiN, realizado, porém, com C5.
2.6 Registro e Análise de dados
A precisão das respostas de tato, ouvinte seleção e IDMTS foi registrada a cada tentativa durante as sessões de testes, sondas de BiN e treino de MEI. Os dados foram analisados considerando-se a porcentagem de respostas de tato e ouvinte seleção corretas nas sondas de BiN e no teste de generalização, além do número de sessões necessárias para atingir o critério de aprendizagem em cada um dos tratamentos.
2.7 Concordância entre observadores e integridade do procedimento
A partir dos vídeos das sessões experimentais, outro pesquisador fez o registro do desempenho de cada participante em 30% das sessões de cada etapa do estudo para estabelecer um índice de concordância entre observadores ([Concordância/Concordância + Discordância] x 100) e, além disso, foi feito o registro via protocolo previamente elaborado da integridade do procedimento, para verificar se os procedimentos de cada etapa do estudo foram implementados corretamente para cada participante ([Implementações corretas/ Total de Implementações] x 100). O índice de concordância entre observadores nas sondas de BiN, linha de base, tratamento MEI e tratamento SPOP foram, respectivamente, 96%, 100%, 99% e 100% para P1, 94%, 94%, 96% e 98% para P2, 98%, 100%, 94% e 100% para P3, e 97%, 100%, 97% e 89% para P4. E os percentuais de integridade do procedimento nas sondas de BiN, linha de base, tratamento MEI e tratamento SPOP foram, respectivamente, 100%, 100%, 98% e 99% para P1, 99%, 100%, 99% e 99% para P2, 100%, 100%, 100% e 100% para P3 e 99%, 100%, 99% e 98% para P4.
3 Resultados
As Figuras 2 e 3 mostram o percentual de respostas independentes corretas de tato e ouvinte ao logo de todas as etapas do procedimento a partir da sonda inicial de BiN. Nas sondas iniciais e linha de base, nenhum participante demonstrou o repertório de BiN. Ao analisar-se o efeito isolado de cada tratamento, observa-se que os participantes submetidos em primeiro lugar ao MEI (P1 e P3) não obtiveram nenhuma melhora nos desempenhos de tato e ouvinte após o treino MEI 1 em relação aos seus desempenhos nas sondas iniciais de BiN e linha de base. Foram necessárias sete sessões para que P1 atingisse critério de aprendizagem no MEI 1 e quatro para P2.
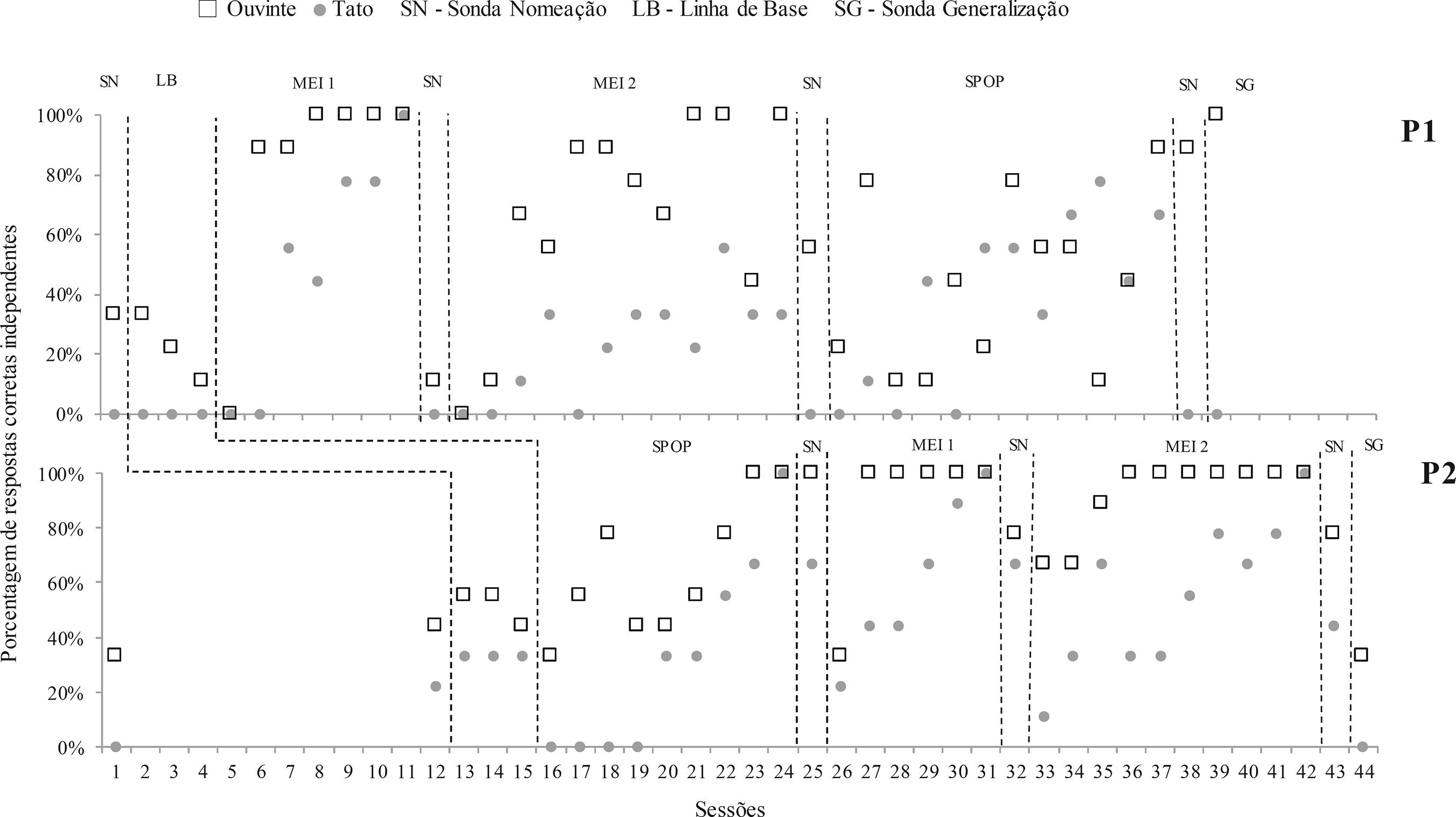
Fonte: Elaborada pelos autores a partir dos dados da pesquisa.
Figura 2 Porcentagem de respostas corretas independentes nos repertorios de tato e ouvinte nas sondas de BiN com C1, nas sessoes de treino de MEI com C2 e C3, nas sondas de tato e ouvinte com C4 realizadas a cada sessao de SPOP e na sonda de generalizacao realizada com C5, para P1 e P2.
Fonte: Elaborada pelos autores a partir dos dados da pesquisa.
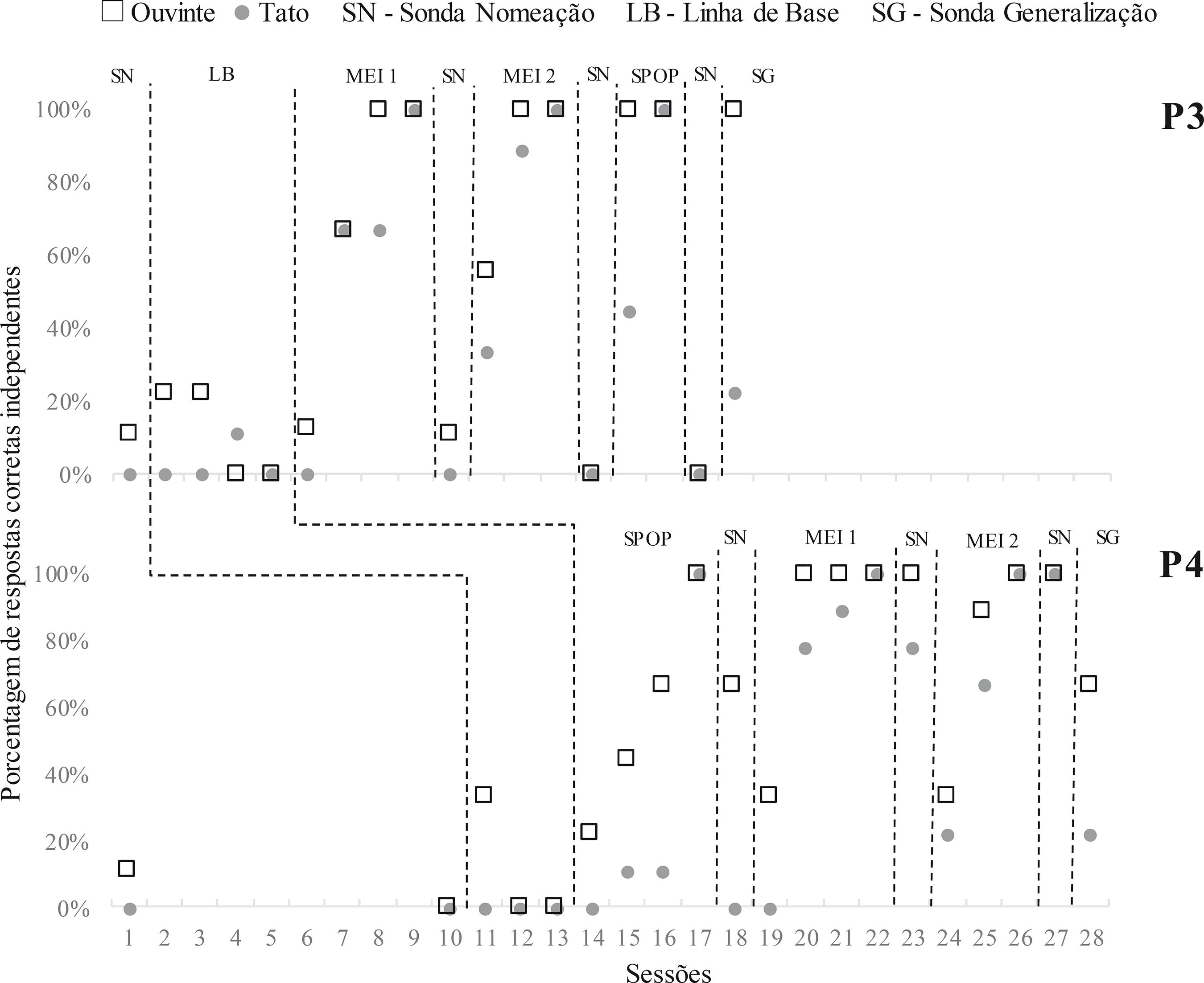
Figura 3 Porcentagem de respostas corretas independentes nos repertorios de tato e ouvinte nas sondas de BiN com C1, nas sessoes de treino de MEI com C2 e C3, nas sondas de tato e ouvinte com C4 realizadas a cada sessao de SPOP e na sonda de generalizacao realizada com C5, para P3 e P4.
No treino MEI 2, o participante P1 atingiu o critério de interrupção do tratamento (12 sessões sem atingir critério de aprendizagem), ainda que tenha atingido critério para o repertório de ouvinte. Na sonda após o treino MEI 2, P1 apresentou aumento no repertório de ouvinte (56%), apresentando, para um dos estímulos, 100% de resposta corretas, mas nenhum ganho em relação ao repertório de tato. Já P3 precisou de três sessões para atingir critério de aprendizagem no treino MEI 2. Na sonda pós MEI 2, apresentou, porém, respostas que indicavam a formação de relações erradas entre os estímulos auditivos e visuais do C1 (o participante nomeava o estímulo visual BIPE de “Dedé” e o estímulo DEDE de “Make” consistentemente em todas as tentativas). Isso aconteceu tanto nas tentativas de tato como nas de ouvinte. Por isso, o desempenho de P3 foi de 0% para os dois repertórios na sonda pós MEI 2. Em relação aos participantes que iniciaram o treino pelo tratamento SPOP, ambos tiveram aumento de desempenho de ouvinte em relação à linha de base (100% - P2 e 67% - P4), mas somente P2 apresentou aumento do repertório de tato (67%, sendo 100% de respostas corretas para dois estímulos do conjunto). Foram necessárias nove sessões para P2 atingir critério de aprendizagem no SPOP e quatro para P4.
Após o segundo tratamento implementado (SPOP para P1 e P3), P1 apresentou 89% de acertos no repertório de ouvinte e 0% no de tato na sonda pós treino, não tendo atingido critério de aprendizagem com C4 até a décima segunda sessão. Já P3 apresentou na sonda pós SPOP o mesmo problema apresentado na sonda pós MEI 2 (formação das mesmas relações erradas entre os estímulos auditivos e visuais do C1), e assim seu desempenho foi de 0% para ambos os repertórios. Devido a esse problema, e considerando-se o excelente desempenho que P3 teve no treino SPOP (atingindo critério em apenas duas sessões com o Conjunto C4), optou-se por realizar a sonda de generalização com P3, ainda que esse participante não tivesse atingido critério de BiN em nenhum dos repertórios com conjunto inicial.
Quanto a P2, após o MEI 1 (segundo tratamento implementado), não houve diferença no repertório de tato em relação à sonda anterior (67%), enquanto o desempenho de ouvinte diminuiu (78%). Esse participante precisou de seis sessões para atingir critério de aprendizagem no MEI 1. Na sonda pós MEI 2, o desempenho de P2 no teste de tato caiu para 44% e o de ouvinte manteve-se em 78% (com somente um erro para dois dos estímulos do conjunto), ele precisou de dez sessões para atingir critério de aprendizagem no MEI 2. Já P4, que seguiu a mesma sequência de treino de P2, apresentou aumento no desempenho de tato (78%, com dois erros para um dos estímulos do conjunto) e ouvinte (100%) na sonda pós MEI 1, no qual atingiu critério de aprendizagem com quatro sessões. Na sonda pós MEI 2, P4 apresentou 100% de acertos em ambos os repertórios, ele levou três sessões para atingir critério de aprendizagem nesse treino.
Nenhum dos participantes emitiu respostas de tato corretas nos testes iniciais com C5. Quanto aos testes iniciais de ouvinte, os resultados foram 11% para P1, 67% para P2, 44% para P3 e 0% para P4. Já nas sondas de generalização (ver Figuras 2 e 3), P1 e P3 apresentaram desempenho de 100% no teste de ouvinte, mas de 0% e 22%, respectivamente, no teste de tato. O resultado de P2 foi 0% para tato e 33% para ouvinte, indicando que seu alto desempenho nos testes iniciais de ouvinte foi devido ao acaso. Enquanto P4 apresentou um aumento em relação a seu desempenho inicial nas sondas de BiN, com 22% no teste de tato e 67% no teste de ouvinte.
4 Discussão
Este estudo buscou comparar a eficiência dos procedimentos de MEI e SPOP para induzir BiN em crianças com TEA, uma vez que os dois procedimentos têm sido relatados em estudos científicos como eficazes para produzir esse repertório, ou pelo menos seus componentes de tato ou de ouvinte. Os dados indicam que o SPOP se mostrou mais eficiente em relação ao aumento no desempenho de tato e ouvinte dos participantes nas sondas pós-treino quando este foi o primeiro tratamento aplicado, assim como ao número de sessões necessárias para que os participantes atingissem critério de aprendizagem. No entanto, a sequência de treino na qual foi aplicado, inicialmente, o MEI e, depois, o SPOP mostrou-se mais eficiente para a generalização do repertório de BiN para um novo conjunto de estímulos.
É importante notar que os dados indicam que somente P2 apresentou respostas de falante (tato) após o SPOP nas sondas de nomeação, sendo este o único participante que apresentou respostas de tato corretas nas sondas iniciais e em todas as sessões de linha de base. Além disso, apresentou os maiores percentuais de acertos de ouvinte durante a linha de base. Por outro lado, P4, que não apresentou nenhuma resposta de tato correta nas sondas iniciais e linha de base, apresentou nas sondas após o MEI, indicando que o MEI pode ser mais efetivo quando o indivíduo ainda não apresenta relações emergentes de tato de ouvinte diante da exposição a pareamentos nome-objeto.
Os dados dos participantes P1 e P3, que tiveram o MEI como primeiro tratamento aplicado, revelam que este não foi eficaz para produzir BiN, mesmo após a exposição a dois treinos de MEI, com dois conjuntos diferentes. Esse resultado vai de encontro aos resultados encontrados por outros estudos que utilizaram o MEI para induzir a BiN (Fiorile & Greer, 2007; Greer et al., 2005; Greer, Stolfi, & Pistoljevic, 2007; Hawkins et al., 2009; Olaff, Ona, & Holth, 2017; Santos & Souza, 2016).
A divergência encontrada neste estudo em relação aos estudos anteriores pode ter sido influenciada por problemas específicos que os participantes apresentaram ao longo da aplicação do procedimento. P1 atingiu critério de aprendizagem no MEI 1 em sete sessões, porém, no treino MEI 2, apresentou respostas que indicavam generalização de estímulos entre dois dos estímulos do C3 (usado no MEI 2) e um dos estímulos do C2 (usado no MEI 1), que apresentavam similaridades formais entre si. Assim sendo, o participante cometeu vários erros por nomear os estímulos do C3 com o mesmo nome que aprendeu para o estímulo do C2, e o procedimento de correção não foi suficiente para sanar esse problema. No caso de P3, ele apresentou rápida aquisição dos três repertórios treinados, tanto no MEI 1 (quatro sessões para atingir critério), quanto no MEI 2 (três sessões), porém, na sonda de BiN pós MEI 2, o participante apresentou formação de relações nome-objeto erradas com estímulos de C1, conforme descrito nos resultados. Uma possível explicação para esse fato é que a tarefa de IDMTS com tato do estímulo modelo pelo experimentador não tenha sido suficiente para garantir a resposta de observação do participante para os estímulos auditivos e visuais relevantes em cada tentativa, o que impediu que a relação correta entre eles fosse estabelecida (Longano & Greer, 2015).
No caso dos participantes que foram submetidos primeiro ao SPOP, os dados nas sondas pós-treino mostram que um dos participantes (P2) apresentou emergência do componente de ouvinte da BiN e aumento do repertório de tato em relação à linha de base. Já P4, embora não tenha demonstrado emergência de nenhum dos componentes da BiN, apresentou aumento no desempenho de ouvinte em relação à linha de base. Pode ter contribuído para esse resultado o fato de que a configuração do treino de SPOP se aproxima mais das sondas de BiN do que a configuração do treino de MEI.
Além disso, é preciso lembrar que o SPOP por si só já produz BiN com o conjunto de estímulos utilizado nesse tratamento (C4), pois as respostas de tato e ouvinte não foram ensinadas diretamente, mas, sim, testadas após cada ciclo de pareamentos. Assim sendo, o SPOP foi eficaz para produzir BiN completa com três dos participantes (P2, P3 e P4), mesmo com número de sessões inferior às necessárias para o treino MEI, se somarmos as sessões do MEI 1 e do MEI 2. Esses dados corroboram com os estudos que demonstram que o SPOP é um procedimento eficaz para produzir emergência de repertórios verbais sem treino direto, como tato e ouvinte (Byrne, Rehfeldt, & Aguirre, 2014; Carnerero & Pérez-González, 2014; Carnerero & Pérez-González, 2015; Longano & Greer, 2015; Rosales, Rehfeldt, & Huffman, 2012).
O fato de os participantes não terem atingido critério para BiN com C1 após o SPOP pode estar relacionado ao fato de eles terem sido expostos a esse tratamento com somente um conjunto de estímulos. No estudo de Longano e Greer (2015), no qual os participantes atingiram critério para nomeação completa após o procedimento de observação de pareamento auditivos-visuais, todos os participantes precisaram ser expostos a mais de um conjunto para adquirir a BiN completa. Além disso, no estudo de Longano e Greer (2015), os estímulos utilizados passaram por procedimento prévio de condicionamento de reforçadores, o que não foi feito neste estudo. Estudos futuros podem investigar se o procedimento de SPOP seria mais eficiente na indução do repertório de BiN se fossem utilizados estímulos auditivos e visuais previamente condicionados como reforçadores.
Alguns participantes chegaram a emitir tatos espontâneos de estímulos do C4 durante as sessões de SPOP (P1 e P4), que não puderam ser reforçados. Esse dado, embora não medido diretamente neste estudo, leva-nos a refletir sobre o papel do reforçamento no processo de aquisição da BiN. Horne e Lowe (1996) descrevem que, no início desse processo, a ocorrência de respostas de ouvinte e tato são reforçadas pelos cuidadores, o que nos leva a questionar se o SPOP aliado com reforçamento de respostas verbais espontâneas não poderia ser mais efetivo. Estudos futuros podem investigar essa questão.
Um diferencial deste estudo em relação a estudos anteriores que também aplicaram o SPOP (Byrne, Rehfeldt, & Aguirre, 2014; Carnerero & Pérez-González, 2014; Carnerero & Pérez-González, 2015; Rosales, Rehfeldt, & Huffman, 2012), é que, no presente estudo, esse tratamento foi aplicado em um contexto mais naturalístico, pois os pareamentos eram apresentados aos participantes em situação de brincadeira durante a interação entre criança e experimentadora. Esse contexto assemelha-se a situações cotidianas vivenciadas pelas crianças e à forma como elas naturalmente aprendem relações nome-objeto, o que pode ter favorecido a aprendizagem via SPOP. No entanto, é necessário que novas pesquisas investiguem se há diferença na efetividade do SPOP para o estabelecimento de BiN quando este é aplicado de maneira mais estruturada e quando é aplicado em um contexto mais naturalístico.
Em relação à ordem de apresentação dos tratamentos experimentais, considerando-se os resultados do teste generalização, a sequência mais eficaz foi a que foi implementada primeiro o MEI e depois o SPOP, aplicada aos participantes P1 e P3, pois esses participantes demonstraram emergência do componente de ouvinte da BiN no teste realizado com um novo conjunto de estímulo (C5), no qual eles foram expostos somente a uma sessão de IDMTS com tato do estímulo modelo pela experimentadora. Os resultados de P3, especificamente, sugerem que o MEI pode funcionar como facilitador da aprendizagem de BiN via ensino incidental, como ocorre no SPOP, pois, após ter passado pelos dois treinos de MEI, o participante precisou de apenas duas sessões de SPOP para atingir critério de aprendizagem para tato e ouvinte, emergindo o componente de ouvinte logo na primeira sessão. Os participantes P2 e P4, que foram submetidos à ordem inversa de implementação dos tratamentos experimentais, não atingiram critério para BiN no teste de generalização. Uma possível explicação para esse resultado, considerando que o tratamento SPOP produziu melhores resultados neste estudo, é que o desempenho dos participantes tenha sido produto da recência em relação ao último tratamento aplicado, visto que aqueles participantes que passaram pelo SPOP por último tiveram um resultado melhor no teste de generalização.
Umas das limitações deste estudo foi o uso do mesmo conjunto de estímulos (C1) em todas as sondas de BiN. É possível que os resultados obtidos nas últimas sondas sejam efeito do acúmulo de pareamentos pelos quais os participantes passaram ao longo das sessões de IDMTS que antecediam os testes de tato e ouvinte em cada sonda, e não somente dos tratamentos implementados. Por exemplo, o número de pareamentos que P4 precisou para atingir o critério de aprendizagem no SPOP (36 por estímulo) foi semelhante ao número de pareamentos a que ele foi exposto somando-se todas as sessões de IDMTS das sondas de BiN com C1 (30 por estímulo). Entretanto, seu desempenho no teste de generalização foi consideravelmente melhor em relação à sonda inicial do repertório com C1, o que sugere um efeito de learning set, pois o número de pareamentos necessários para emergência de BiN com novos conjuntos de estímulos pode ir diminuindo à medida que a criança é exposta a ciclos de pareamento com novos conjuntos, o que está de acordo com os resultados de Carnerero e Pérez-Gonzaléz (2014) que mostram que o número de pareamentos necessários para emergência do repertório de tato diminuía à medida que novos conjuntos de estímulos eram apresentados.
No entanto, os resultados obtidos no teste de generalização não estão sujeitos a essa limitação, uma vez que foi utilizado um novo conjunto de estímulos, e, portanto, representam dados confiáveis sobre a aquisição de nomeação após os tratamentos implementados. Em estudos futuros, recomendamos o uso de diferentes conjuntos de estímulos a cada sonda de nomeação. Além disso, poderia ser utilizado um grupo controle que seja exposto somente às sondas de nomeação (com IDMTS) e não passe pelos tratamentos.
5 Conclusão
Este estudo sugeriu que o SPOP pode ser eficaz para induzir BiN em crianças com TEA, e que uma combinação de MEI e SPOP favorece a generalização da BiN. Considerando que a BiN é apontada como um marco no desenvolvimento que possibilita um rápido crescimento do repertório verbal, permitindo que a criança estabeleça relações mais efetivas com o mundo (Horne & Lowe,1996; Greer & Ross, 2008; Greer & Speckman, 2009; Greer & Longano, 2010), esses resultados podem auxiliar na escolha de procedimentos durante o planejamento de intervenções comportamentais eficazes e eficientes para o ensino de habilidades verbais para indivíduos com desenvolvimento atípico.