









 Português (pdf)
Português (pdf)
 Artigo em XML
Artigo em XML
 Enviar este artigo por email
Enviar este artigo por email
 Permalink
Permalink
1 Introdução
O modelo de dupla rota de leitura em voz alta postula que existem duas rotas da palavra impressa à fala: uma rota lexical e uma não lexical – essa última também chamada de rota fonológica. Dessa maneira, Coltheart et al. (1993) informam que a leitura pela rota lexical depende do conhecimento da palavra no léxico mental1 e que a leitura pela rota não lexical ou fonológica não depende desse léxico. Portanto, a leitura oral de um texto escrito pode ocorrer por meio de um processo visual direto ou por meio de um processo envolvendo mediação fonológica.
A leitura fonológica grafema-fonema é um processo de leitura por meio do qual o leitor, especialmente em processo inicial de aprendizagem da leitura, relaciona os sons às letras ou a combinações de letras, consumindo, nesse processo de conversão, os recursos cognitivos disponíveis, por não haver processamento automatizado – logo, sem que haja condições para o acesso pleno ao léxico mental ou ao significado. Assim, a leitura pela via fonológica depende da utilização do conhecimento das regras de conversão entre grafema e fonema para a construção da pronúncia de uma palavra.
A leitura pela rota lexical, por sua vez, caracteriza-se pelo reconhecimento automatizado de uma palavra previamente adquirida e memorizada, portanto presente no léxico mental, e pela recuperação de seu significado e de sua pronúncia por meio de um endereçamento direto ao léxico (Pinheiro, Lúcio e Silva, 2008). Em relação à compreensão leitora, Dehaene (2012, p. 245) defende que “a compreensão passa antes de tudo pela fluência da decodificação. Quanto mais rápido essa etapa for automatizada, melhor o aluno poderá se concentrar no significado do texto”.
Encontra-se documentado na literatura que a extensão das palavras interfere de alguma forma na conversão grafofonêmica, tanto no tempo de conversão quanto na precisão de conversão, também tecnicamente chamada de acurácia, e que esse efeito da característica das palavras diminui à medida que o leitor automatiza o processamento visual das letras e acessa o seu valor sonoro2. Neste estudo, pretendemos avaliar o efeito da extensão das palavras na conversão grafofonêmica – particularmente na variável tempo de conversão – de escolares do 2º, 3º e 4º anos do Ensino Fundamental. Devido ao que documenta a literatura, trabalhamos com a hipótese de que quanto maior for a extensão da palavra, tanto maior será o tempo médio de conversão de cada grafema.
A seguir, constam seções de revisão e aporte teórico, desenho metodológico do estudo, resultados e discussão e considerações finais.
2 Revisão da literatura e aporte teórico
O efeito de extensão tem sido explicado pelo uso preferencial da rota fonológica, que, como concluem pesquisas com crianças brasileiras, manifesta-se, sobretudo, no início da aprendizagem da língua escrita, fase em que quanto maior o número de letras na palavra, mais lenta e menos precisa é a leitura (Pinheiro, 1994, 2008). Salles e Parente (2002, 2007), em pesquisas com crianças do 1º e do 2º anos, concluíram que o efeito de extensão foi elevado, principalmente na escrita. Em pesquisa longitudinal, Godoy (2005, p. 141) acompanhou crianças da pré-escola ao final do 1º ano e verificou que houve efeito de extensão na escrita, “indicando que as palavras curtas foram escritas mais corretamente que as palavras longas”, e também na leitura.
Vários são os estudos que sugerem que a rota fonológica, por permitir a aplicação das regras de correspondência grafema-fonema, possibilita a leitura das palavras regulares, das irregulares e das pseudopalavras. No entanto, tal aplicação de regras na leitura por esses leitores impacta a leitura das palavras irregulares, devido à relação arbitrária entre ortografia e fonologia de um ou mais componentes. Distintamente, na rota lexical, o leitor tende a realizar o acesso à palavra pela sua representação ortográfica, o que proporciona a ativação direta das representações semântica e fonológica. A leitura pela rota lexical permite o reconhecimento de palavras familiares e irregulares – ao se visualizar a palavra, ela será recuperada no léxico mental, que contém o conhecimento visual da ortografia das palavras, ou seja, os padrões de ortografia que caracterizam a palavra ou parte dela, bem como a pronúncia desses padrões ou partes das palavras e seu significado (Capellini, Oliveira e Cuetos, 2014; Coltheart, 2013; Cuetos, 2010; Mehlhase et al., 2020; Morais, 2013; Oliveira, 2017; Pinheiro, 2001, 2006; Pinheiro, Lúcio e Silva, 2008; Pinheiro e Rothe-Neves, 2001; Snowling e Hulme, 2013).
Tendo como principal objetivo a investigação do desenvolvimento da leitura e da escrita em crianças brasileiras, o estudo de Pinheiro (1995) contou com uma amostra de 80 crianças da 1ª à 4ª séries (20 crianças de cada série), julgadas por suas professoras como estudantes com boas habilidades de leitura e de escrita. A pesquisa preocupou-se com a análise das medidas de tempo de reação e porcentagem de erros de leitura e escrita de palavras e pseudopalavras. O estudo observou que o efeito de lexicalidade foi estatisticamente significativo para todas as séries nas comparações entre pseudopalavras e palavras de baixa frequência, sendo as pseudopalavras lidas mais lentamente e com menos acurácia do que as palavras.
O estudo de Capovilla et al. (1997) investigou o efeito das variáveis lexicalidade, frequência de ocorrência, regularidade e comprimento em três variáveis dependentes: padrão de segmentação, tempo de reação locucional e duração locucional. Para tanto, os autores utilizaram uma tarefa de leitura em voz alta e contaram com uma amostra de 35 estudantes brasileiros de um curso de graduação em Psicologia. Utilizando uma análise de variância, Capovilla et al. (1997) encontraram um efeito de lexicalidade para todas as três variáveis dependentes investigadas, isto é, as pseudopalavras produziram significativamente maior tempo de reação, maior duração locucional e maior padrão de segmentação do que as palavras.
Segundo Dehaene (2012), a via de decodificação grafema-fonema implica essencialmente as regiões superiores do lobo temporal esquerdo. Além disso, diante da visão de uma letra, toda uma parte do lobo temporal é ativada. No entanto, somente uma região superior do lobo temporal (planum temporale) reage à compatibilidade entre as letras e os sons, aumentando a atividade nessa região. Em contrapartida, o conflito entre letra e som se traduz em uma redução dessa atividade. Nas palavras de Dehaene (2012, p. 245), “a decodificação fonológica é a chave para a leitura [...] que transforma radicalmente o cérebro da criança e sua forma de escutar os sons da fala”.
3 Método
3.1 Participantes
A presente pesquisa, aprovada pelo Comitê de Ética em Pesquisa da Universidade Estadual do Sudoeste da Bahia, UESB, sob CAAE: 1595.9413.6.0000.0055, parecer número 427.086, contemplou escolares do 2º ao 4º anos do Ensino Fundamental I, sendo sete do 2º ano, seis do 3º e cinco do 4º, totalizando 18 alunos. O grupo de participantes foi composto por escolares de ambos os gêneros, na faixa etária de 8 a 10 anos, da rede pública municipal e da rede particular de ensino do município de Brumado, Bahia, Brasil. Os escolares precisavam apresentar acuidades visual e auditiva e desempenho cognitivo dentro dos padrões da normalidade, conforme descrição no prontuário escolar e relato dos professores, além de conseguir ler sem ajuda, ou seja, realizar a leitura de forma autônoma.
3.2 Materiais e procedimentos
No intuito de avaliar a influência do efeito de extensão no tempo de processamento da leitura oral de palavras e pseudopalavras isoladas em escolares do 2º ao 4º anos, distribuímos 180 palavras isoladas: 60 regulares, 60 irregulares, 60 pseudopalavras. Em outra divisão, ainda, as palavras foram categorizadas em 60 palavras/pseudopalavras de até quatro grafemas (sendo 20 palavras regulares, 20 palavras irregulares e 20 pseudopalavras), 60 de cinco a sete grafemas (sendo igualmente 20 palavras regulares, 20 palavras irregulares e 20 pseudopalavras) e 60 com oito ou mais grafemas (também 20 palavras regulares, 20 palavras irregulares e 20 pseudopalavras), conforme a Tabela 1.
Tabela 1 Distribuição de palavras pelas características de extensão e regularidade.
| Palavras regulares | Palavras irregulares | Pseudopalavras | |||
|---|---|---|---|---|---|
| 4 grafemas ou menos | 20 | 20 | 20 | 60 | 180 |
| De 5 a 7 grafemas | 20 | 20 | 20 | 60 | |
| 8 grafemas ou mais | 20 | 20 | 20 | 60 | |
| Total de palavras isoladas: 180 | |||||
Fonte: Autoria própria.
Procedemos à organização e à descrição sumária dos dados considerando as médias de conversão para cada categoria de extensão. Julgamos que trabalhar com a média de conversão grafofonêmica seria o indicador quantitativo mais indicado diante da variabilidade no número de grafemas de cada palavra, estando essas dentro das categorias: 1) quatro grafemas ou menos; 2) entre cinco e sete grafemas; 3) oito grafemas ou mais. Para se chegar a esse indicador quantitativo, cronometrou-se o tempo levado pelo participante leitor para a conversão de cada palavra. Em seguida, dividiu-se o tempo de leitura de cada item (palavra regular, palavra irregular e pseudopalavra) pela quantidade de grafemas daquele item.
O instrumento de coleta de palavras isoladas e pseudopalavras foi organizado pelos pesquisadores, de modo que as palavras adotadas na pesquisa foram selecionadas segundo critérios que atendessem aos efeitos de lexicalidade, extensão e regularidade. A seleção das palavras atendeu aos objetivos propostos e se mostrou de acordo com os princípios do sistema alfabético do Português do Brasil (Scliar-Cabral, 2003). Na tentativa de identificar a consistência interna dos constituintes, ou a inconsistência de alguma palavra/pseudopalavra, os constituintes de cada categoria foram avaliados por meio do coeficiente alfa de Cronbach, que é calculado a partir da variância dos constituintes de cada categoria. Os resultados (todos acima de 0,93) aferem a alta consistência interna de seus elementos, o que mostra acerto na escolha das palavras para cada uma das categorias do instrumento utilizado.
Em razão da pandemia, as escolas estavam fechadas. Por esse motivo, a coleta de dados aconteceu com cada participante individualmente, em uma sala dentro do Núcleo de Apoio à Aprendizagem (Naap), que é um espaço de acompanhamento multiprofissional na cidade do estudo, sendo rigorosamente seguidas as orientações sanitárias para o período. Após o término de cada gravação, todo o equipamento e os móveis eram higienizados.
Para gravação da leitura oral dos escolares, foi utilizado o software Audacity, com frequência de amostragem de 44.100 Hz, e um microfone Karsect (cardioide) de cabeça unidirecional. O equipamento foi conectado a um notebook, e os arquivos resultantes das gravações foram salvos na extensão way file. A opção pelo microfone cardioide deu-se por ele possuir um mecanismo por meio do qual o som é captado com maior intensidade pelo lado para onde o equipamento está direcionado, enquanto outros sons são gravados com menor intensidade.
O microfone foi posicionado na cabeça da criança, a uma distância de cerca de 6 a 9 cm da boca do escolar, em um ângulo de aproximadamente 45º. O microfone foi conectado a um notebook da marca Acer, com um processador do tipo Intel Core, memória de 5 GB, sistema operacional de 32 bits.
O tempo de leitura de cada palavra foi cronometrado e, inicialmente, registrado em segundos em uma planilha de Excel. Em seguida, foi calculada a taxa de conversão grafofonêmica de cada palavra, que consistiu na divisão do tempo de leitura da palavra pela quantidade de grafemas (tempo ÷ quantidade de grafemas).
4 Resultados e discussão
4.1 Da avaliação do efeito de extensão do conjunto total de palavras/pseudopalavras na leitura oral
Para a comparação de resultados entre as categorias de extensão (quatro grafemas ou menos, entre cinco e sete grafemas e oito grafemas ou mais), consideraram-se as médias de conversões grafofonêmicas dos participantes em cada uma dessas categorias. Tais dados constam na Tabela 2.
Tabela 2 Médias de conversão grafofonêmica pelas categorias extensão e transparência em milésimos de segundo.
| Palavras regulares | Palavras irregulares | Pseudopalavras | ||||||
|---|---|---|---|---|---|---|---|---|
| PIRE-4 | PIRE5-7 | PIRE8+ | PIIR-4 | PIIR5-7 | PIIR8+ | PIPS-4 | PIPS5-7 | PIPS8+ |
| 0,280 | 0,238 | 0,217 | 0,247 | 0,255 | 0,274 | 0,314 | 0,251 | 0,310 |
| 0,187 | 0,167 | 0,167 | 0,209 | 0,189 | 0,237 | 0,254 | 0,238 | 0,248 |
| 0,299 | 0,251 | 0,239 | 0,308 | 0,366 | 0,250 | 0,345 | 0,340 | 0,352 |
| 0,233 | 0,175 | 0,147 | 0,209 | 0,179 | 0,164 | 0,251 | 0,292 | 0,231 |
| 0,207 | 0,253 | 0,399 | 0,271 | 0,395 | 0,395 | 0,366 | 0,361 | 0,425 |
| 0,210 | 0,255 | 0,314 | 0,317 | 0,314 | 0,293 | 0,362 | 0,296 | 0,355 |
| 0,297 | 0,235 | 0,290 | 0,273 | 0,300 | 0,245 | 0,305 | 0,260 | 0,245 |
| 0,208 | 0,165 | 0,146 | 0,205 | 0,191 | 0,156 | 0,219 | 0,221 | 0,193 |
| 0,263 | 0,170 | 0,142 | 0,241 | 0,206 | 0,149 | 0,242 | 0,191 | 0,169 |
| 0,252 | 0,177 | 0,155 | 0,242 | 0,213 | 0,179 | 0,275 | 0,227 | 0,196 |
| 0,214 | 0,226 | 0,287 | 0,259 | 0,298 | 0,295 | 0,313 | 0,298 | 0,316 |
| 0,150 | 0,177 | 0,234 | 0,216 | 0,185 | 0,187 | 0,237 | 0,191 | 0,223 |
| 0,249 | 0,178 | 0,155 | 0,243 | 0,205 | 0,149 | 0,288 | 0,209 | 0,193 |
| 0,222 | 0,141 | 0,124 | 0,218 | 0,163 | 0,118 | 0,230 | 0,181 | 0,160 |
| 0,235 | 0,170 | 0,132 | 0,236 | 0,180 | 0,140 | 0,249 | 0,173 | 0,197 |
| 0,205 | 0,152 | 0,162 | 0,200 | 0,193 | 0,173 | 0,199 | 0,193 | 0,226 |
| 0,255 | 0,187 | 0,146 | 0,263 | 0,189 | 0,141 | 0,294 | 0,197 | 0,163 |
| 0,204 | 0,145 | 0,189 | 0,234 | 0,201 | 0,194 | 0,259 | 0,271 | 0,276 |
Legenda: PIRE-4: palavras isoladas regulares com quatro grafemas ou menos; PIRE5-7: palavras isoladas regulares com cinco a sete grafemas; PIRE8+: palavras isoladas regulares com oito grafemas ou mais; PIIR-4: palavras isoladas irregulares com quatro grafemas ou menos; PIIR5-7: palavras isoladas irregulares com cinco a sete grafemas; PIIR8+: palavras isoladas irregulares com oito grafemas ou mais; PIPS-4: pseudopalavras isoladas com quatro grafemas ou menos; PIPS5-7: pseudopalavras isoladas com cinco a sete grafemas; PIPS8+: pseudopalavras isoladas com oito grafemas ou mais.
Fonte: Autoria própria.
Em seguida, procedemos à obtenção da média de conversão por categoria de extensão, ou seja, como exemplo, foram somados os resultados da categoria quatro grafemas ou menos nas três categorias de transparência (regulares, irregulares e pseudopalavras). Exemplificando, o primeiro sujeito dessa categoria obteve uma média de 0,280, a qual foi resultado da média de conversão das palavras regulares (0,280), mais a média de conversão das palavras irregulares (0,247), mais a média de conversão das pseudopalavras (0,314). A soma resultou em 0,841. Essa soma foi dividida por 3, número das categorias de regularidade (regulares, irregulares e pseudopalavras), o que resultou na média de conversão dos participantes para cada uma das categorias de extensão – nesse caso exemplificativo, 0,280.
O mesmo procedimento foi realizado para a obtenção da média de conversão de todos os sujeitos nas demais categorias de extensão. Os resultados constam na Tabela 3, conforme dados relativos às médias de conversão das palavras por extensão.
Tabela 3 Médias de conversão por categoria de extensão em milésimos de segundo.
| 4 grafemas ou menos | De 5 a 7 grafemas | 8 grafemas ou mais |
|---|---|---|
| 0,280 | 0,248 | 0,267 |
| 0,217 | 0,198 | 0,217 |
| 0,317 | 0,319 | 0,280 |
| 0,231 | 0,215 | 0,181 |
| 0,281 | 0,336 | 0,406 |
| 0,296 | 0,288 | 0,321 |
| 0,292 | 0,265 | 0,260 |
| 0,211 | 0,192 | 0,165 |
| 0,249 | 0,189 | 0,153 |
| 0,256 | 0,206 | 0,177 |
| 0,262 | 0,274 | 0,299 |
| 0,201 | 0,184 | 0,215 |
| 0,260 | 0,197 | 0,166 |
| 0,223 | 0,162 | 0,134 |
| 0,240 | 0,174 | 0,156 |
| 0,201 | 0,179 | 0,187 |
| 0,196 | 0,216 | 0,218 |
| 0,179 | 0,235 | 0,269 |
Fonte: Autoria própria.
A comparação estatística das categorias de extensão e a consequente avaliação das diferenças observadas serão empreendidas adiante por meio de ferramenta estatística específica para esse fim. Todavia, observando os resultados da leitura oral dos diferentes grupos, por meio de sua descrição estatística, é possível constatar que: 1) os participantes levaram em média apenas 0,244 milésimos de segundo para a conversão de cada grafema do grupo de até quatro grafemas ou menos; 2) 0,227 milésimos de segundo para as palavras com cinco a sete grafemas; 3) 0,226 milésimos de segundo para grafemas no grupo de palavras/pseudopalavras com oito grafemas ou mais.
O passo seguinte foi tratar estatisticamente os dados com uma ferramenta apropriada para o fim pretendido neste estudo. Como se trata de comparação entre resultados de um mesmo indivíduo lendo palavras em três categorias de tamanhos diferentes (quatro grafemas ou menos; cinco a sete grafemas; oito grafemas ou mais), o teste escolhido e o mais recomendado para esse contexto de processamento de dados4 – o qual pode ser caracterizado como não paramétrico5, com comparação pareada de medidas6, entre três grupos ou mais – foi o teste de Friedman7.
O resultado do teste de Friedman, considerando as médias de conversão grafofonêmica dos três grupos constituídos pela extensão, foi de 0,163. Ou seja, esse resultado mostra que não há diferença estatística entre os grupos, pois o valor observado de p foi de 0,163. Isto é, no contexto geral dos participantes avaliados (2º, 3º e 4º anos), a extensão da palavra não interferiu na leitura oral. Diante desse resultado (ausência de diferença estatisticamente significativa entre os grupos constituídos em função da extensão das palavras/pseudopalavras), não julgamos apropriada a comparação entre os grupos. Tal cálculo se justifica quando o valor de p é igual ou menor que 0,05.
Tendo em vista esse resultado, e considerando a soma dos componentes da categoria de regularidade, quisemos avaliar o possível impacto de cada uma das categorias, a saber: palavras regulares, palavras irregulares e pseudopalavras.
4.2 Da avaliação do efeito de extensão na leitura oral de palavras regulares
O mesmo procedimento estatístico adotado para os dados gerais foi adotado para avaliar o possível efeito da extensão na leitura de palavras regulares. Na Tabela 4, é possível visualizar os dados correspondentes às médias de leitura oral dessas palavras.
Tabela 4 Médias de conversão das palavras regulares por categoria de extensão em milésimos de segundo.
| Palavras regulares | ||
|---|---|---|
| PIRE-4 | PIRE5-7 | PIRE8+ |
| 0,280 | 0,238 | 0,217 |
| 0,187 | 0,167 | 0,167 |
| 0,299 | 0,251 | 0,239 |
| 0,233 | 0,175 | 0,147 |
| 0,207 | 0,253 | 0,399 |
| 0,210 | 0,255 | 0,314 |
| 0,297 | 0,235 | 0,290 |
| 0,208 | 0,165 | 0,146 |
| 0,263 | 0,170 | 0,142 |
| 0,252 | 0,177 | 0,155 |
| 0,214 | 0,226 | 0,287 |
| 0,150 | 0,177 | 0,234 |
| 0,249 | 0,178 | 0,155 |
| 0,222 | 0,141 | 0,124 |
| 0,235 | 0,170 | 0,132 |
| 0,205 | 0,152 | 0,162 |
| 0,255 | 0,187 | 0,146 |
| 0,204 | 0,145 | 0,189 |
Legenda: PIRE-4: palavras isoladas regulares com quatro grafemas ou menos; PIRE5-7: palavras isoladas regulares com cinco a sete grafemas; PIRE8+: palavras isoladas regulares com oito grafemas ou mais.
Fonte: Autoria própria.
Ao tratar descritivamente os dados, observamos que os participantes levaram 0,232 milésimos de segundo para converter palavras regulares com quatro grafemas ou menos, 0,192 milésimos de segundo para converter palavras regulares com cinco a sete grafemas e 0,203 milésimos de segundo para converter palavras com oito grafemas ou mais. Ou seja, novamente não se observou efeito de extensão na variável tempo de conversão na leitura oral. Isto é, o fato de a palavra regular lida ser mais extensa não significou dificuldade de leitura – pelo contrário, ela foi convertida mais rapidamente. O tratamento estatístico específico para esse fim demonstra se a diferença é significativa (Tabela 5).
Tabela 5 Descrição estatística das médias de conversão em milésimos de segundo de palavras regulares distinguidas por sua extensão.
| 4 grafemas ou menos | 5 a 7 grafemas | 8 grafemas ou mais | |
|---|---|---|---|
| Média | 0,232 | 0,192 | 0,203 |
| Erro padrão | 0,009 | 0,009 | 0,018 |
| Mediana | 0,228 | 0,177 | 0,165 |
| Modo | #N/D | 0,170 | 0,146 |
| Desvio padrão | 0,039 | 0,039 | 0,077 |
| Variância da amostra | 0,002 | 0,002 | 0,006 |
| Curtose | -0,045 | -1,241 | 0,917 |
| Assimetria | 0,040 | 0,555 | 1,230 |
| Intervalo | 0,149 | 0,114 | 0,275 |
| Mínimo | 0,150 | 0,141 | 0,124 |
| Máximo | 0,299 | 0,255 | 0,399 |
| Soma | 4,170 | 3,462 | 3,645 |
| Contagem | 18 | 18 | 18 |
| Nível de confiança (95%) | 0,0193 | 0,0194 | 0,0382 |
Fonte: Autoria própria.
Como aspecto a ser destacado na descrição estatística apresentada na Tabela 5, vale ressaltar os maiores valores das médias das palavras regulares com oito grafemas ou mais no quesito desvio padrão (DP = 0,077) – quase o dobro em comparação com palavras regulares com quatro grafemas ou menos (DP = 0,039) e com palavras regulares com cinco a sete grafemas (DP = 0,039). A mesma interpretação serve para os demais aspectos da Tabela 5 que tratam de desvios de tendência central. Observa-se, inclusive, na categoria oito grafemas ou mais, um intervalo maior entre os valores mínimo e máximo (0,399) – intervalo bem maior que os das categorias quatro grafemas ou menos (0,299) e cinco a sete grafemas (0,255). Constata-se, ainda, erro padrão maior na categoria de extensão de oito grafemas ou mais (0,018), em comparação com as demais categorias de extensão.
O passo seguinte foi investigar uma possível diferença entre os grupos. Para isso, novamente fizemos uso do teste de Friedman, já que é o teste indicado para tratamento de dados não paramétricos, pareados entre três grupos. O resultado do teste de Friedman, considerando as médias de conversão grafofonêmica das palavras regulares divididas por sua extensão, foi de 0,013. O resultado mostra que houve diferença estatística entre os grupos (0,013), pois o valor de p foi menor que 0,05.
Diante desse resultado, quisemos saber entre quais grupos havia diferença. Para tanto, também utilizamos o teste de Friedman – executado pelo software SPSS8 –, especificamente o modelo de relações simples de Friedman, conforme a Figura 1.
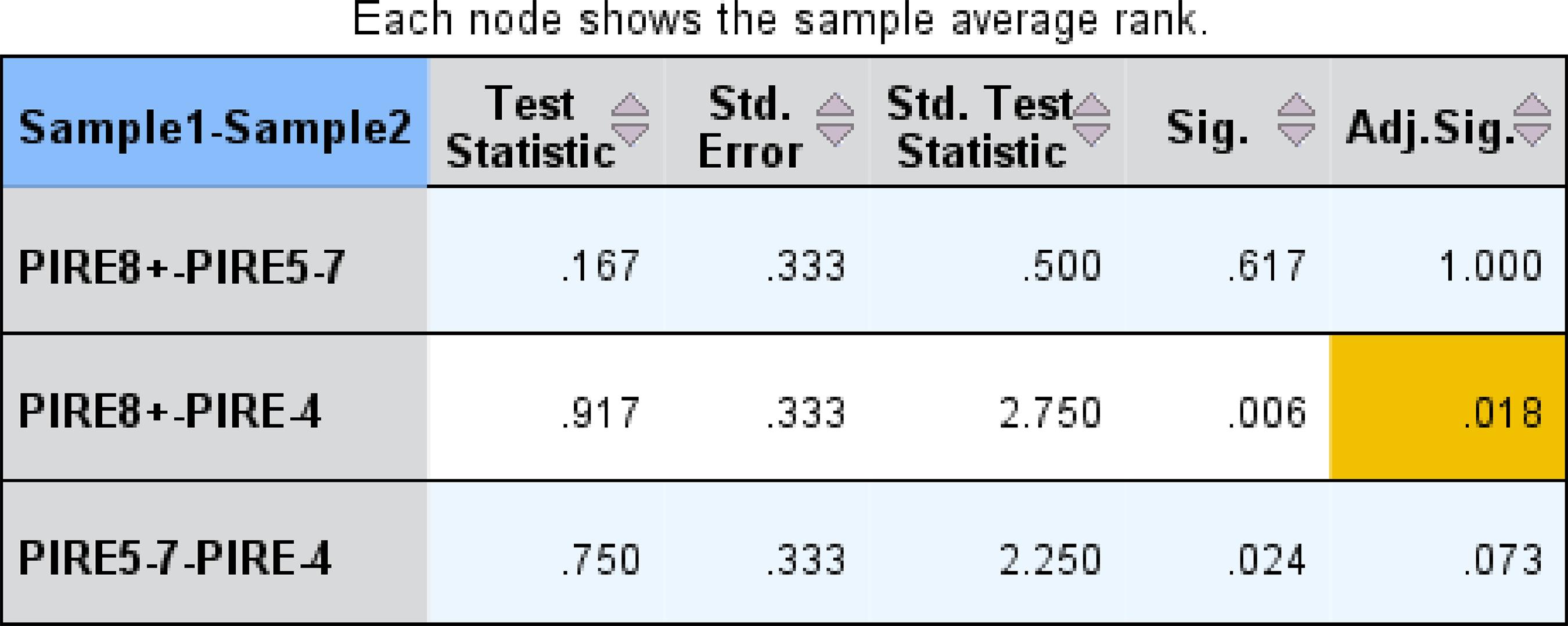
Na Figura 1, na relação par a par, obtida por meio da análise de variância pelo modelo de relações simples de Friedman, podemos observar, na comparação entre as leituras de palavras regulares pelos participantes, que houve diferença estatisticamente significativa apenas entre o grupo de quatro grafemas ou menos e o de oito grafemas ou mais, com valor de p ajustado de 0,018. Diferentemente do que esperávamos, palavras mais extensas foram lidas estatisticamente mais rápido do que palavras curtas.
4.3 Da avaliação do efeito de extensão na leitura oral de palavras irregulares
O mesmo procedimento estatístico foi utilizado para avaliar o possível efeito da extensão na leitura oral de palavras irregulares. Na Tabela 6, é possível visualizar os dados correspondentes às médias de leitura oral dessas palavras.
Tabela 6 Médias de conversão em milésimos de segundo das palavras irregulares por categoria de extensão.
| PIIR-4 | PIIR5-7 | PIIR8+ |
|---|---|---|
| 0,247 | 0,255 | 0,274 |
| 0,209 | 0,189 | 0,237 |
| 0,308 | 0,366 | 0,250 |
| 0,209 | 0,179 | 0,164 |
| 0,271 | 0,395 | 0,395 |
| 0,317 | 0,314 | 0,293 |
| 0,273 | 0,300 | 0,245 |
| 0,205 | 0,191 | 0,156 |
| 0,241 | 0,206 | 0,149 |
| 0,242 | 0,213 | 0,179 |
| 0,259 | 0,298 | 0,295 |
| 0,216 | 0,185 | 0,187 |
| 0,243 | 0,205 | 0,149 |
| 0,218 | 0,163 | 0,118 |
| 0,236 | 0,180 | 0,140 |
| 0,200 | 0,193 | 0,173 |
| 0,263 | 0,189 | 0,141 |
| 0,234 | 0,201 | 0,194 |
Legenda: PIIR-4: palavras isoladas irregulares com quatro grafemas ou menos; PIIR5-7: palavras isoladas irregulares com cinco a sete grafemas; PIIR8+: palavras isoladas irregulares com oito grafemas ou mais.
Fonte: Autoria própria.
Ao submeter os resultados apresentados na Tabela 6 a tratamento estatístico, observamos que os participantes levaram 0,244 milésimos de segundo para converter palavras irregulares com quatro grafemas ou menos, 0,235 milésimos de segundo para converter palavras irregulares com cinco a sete grafemas e 0,208 milésimos de segundo para converter palavras irregulares com oito grafemas ou mais. Isso significa que, novamente, não se observou efeito de extensão na leitura oral. Ou seja, o fato de a palavra irregular lida ser mais extensa não significou dificuldade de leitura – pelo contrário, ela foi convertida mais rapidamente.
O passo posterior foi investigar uma possível diferença entre os grupos. Para isso, fizemos novamente uso do teste de Friedman, já que é o teste indicado para tratamento de dados não paramétricos, pareados entre três grupos. O resultado do teste de Friedman, considerando as médias de conversão grafofonêmica das palavras irregulares pela sua extensão, mostrou que houve diferença estatística entre os grupos, pois o valor de p observado (0,003) foi menor que 0,05.
Diante desse resultado, quisemos saber entre quais grupos havia diferença. Assim, também utilizamos o teste de Friedman no SPSS, especificamente o modelo de relações simples de Friedman, como mostra a Figura 2.
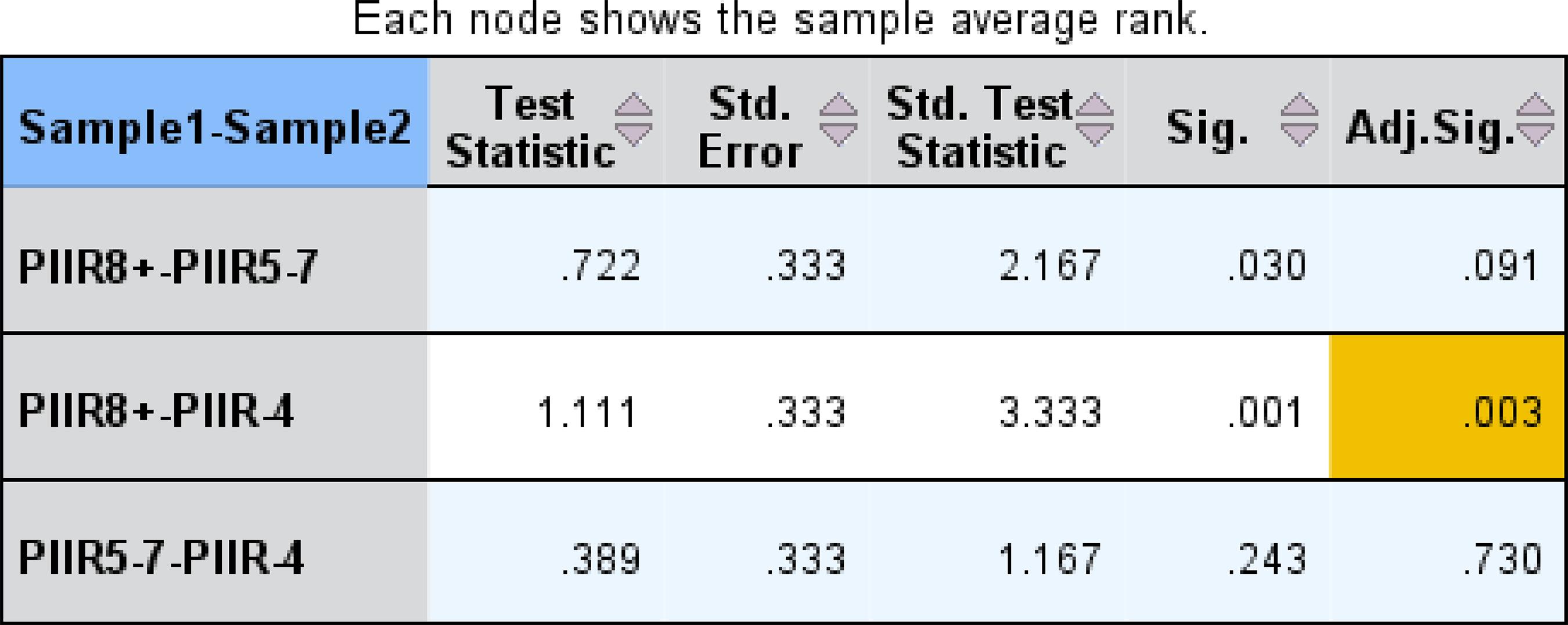
Na Figura 2, na relação par a par, obtida por meio da análise de variância pelo modelo de relações simples de Friedman, podemos observar, na comparação entre as leituras de palavras irregulares pelos participantes, que houve diferença estatisticamente significativa apenas entre o grupo de quatro grafemas ou menos e o de oito grafemas ou mais, com valor de p ajustado de 0,003.
4.4 Da avaliação do efeito de extensão na leitura oral de pseudopalavras
O mesmo procedimento estatístico foi utilizado para avaliar o possível efeito da extensão na leitura oral de pseudopalavras. Na Tabela 7, é possível visualizar os dados correspondentes às médias de leitura oral das pseudopalavras.
Tabela 7 Médias de conversão em milésimos de segundo das pseudopalavras por categoria de extensão.
| PIPS-4 | PIPS5-7 | PIPS8+ |
|---|---|---|
| 0,314 | 0,251 | 0,310 |
| 0,254 | 0,238 | 0,248 |
| 0,345 | 0,340 | 0,352 |
| 0,251 | 0,292 | 0,231 |
| 0,366 | 0,361 | 0,425 |
| 0,362 | 0,296 | 0,355 |
| 0,305 | 0,260 | 0,245 |
| 0,219 | 0,221 | 0,193 |
| 0,242 | 0,191 | 0,169 |
| 0,275 | 0,227 | 0,196 |
| 0,313 | 0,298 | 0,316 |
| 0,237 | 0,191 | 0,223 |
| 0,288 | 0,209 | 0,193 |
| 0,230 | 0,181 | 0,160 |
| 0,249 | 0,173 | 0,197 |
| 0,199 | 0,193 | 0,226 |
| 0,294 | 0,197 | 0,163 |
| 0,259 | 0,271 | 0,276 |
Legenda: PIPS-4: pseudopalavras isoladas com quatro grafemas ou menos; PIPS5-7: pseudopalavras isoladas com cinco a sete grafemas; PIPS8+: pseudopalavras isoladas com oito grafemas ou mais.
Fonte: Autoria própria.
Ao submeter os dados apresentados na Tabela 7 a tratamento descritivo, observamos que os participantes levaram 0,278 milésimos de segundo para converter pseudopalavras com quatro grafemas ou menos, 0,244 milésimos de segundo para converter pseudopalavras com cinco a sete grafemas e 0,249 milésimos de segundo para converter pseudopalavras com oito grafemas ou mais. Ou seja, ao que parece, novamente não se observou efeito de extensão na leitura oral. Isto é, o fato de a pseudopalavra lida ser mais extensa não significou dificuldade de leitura. O tratamento estatístico específico para esse fim demonstra se a diferença é significativa.
Os dados foram submetidos ao teste Friedman, e o resultado mostra que houve diferença estatística entre os grupos, pois o valor de p observado foi de 0,012, menor que 0,05. Diante desse resultado, quisemos saber entre quais grupos havia diferença. Portanto, também utilizamos o teste de Friedman no SPSS, especificamente o modelo de relações simples de Friedman. Na relação par a par, obtida por meio da análise de variância pelo modelo de relações simples de Friedman, podemos observar, na comparação entre as leituras de pseudopalavras pelos participantes, que houve diferença estatisticamente significativa apenas entre o grupo de quatro grafemas ou menos e o de cinco a sete grafemas, com valor de p ajustado de 0,014.
O passo seguinte foi investigar uma possível diferença entre os grupos. Para isso, fizemos novamente uso do teste de Friedman, já que é o teste indicado para tratamento de dados não paramétricos, pareados entre três grupos.
Diante desse resultado, quisemos saber entre quais grupos havia diferença. Assim, também utilizamos o teste de Friedman no SPSS, especificamente o modelo de relações simples de Friedman, consoante a Figura 3.
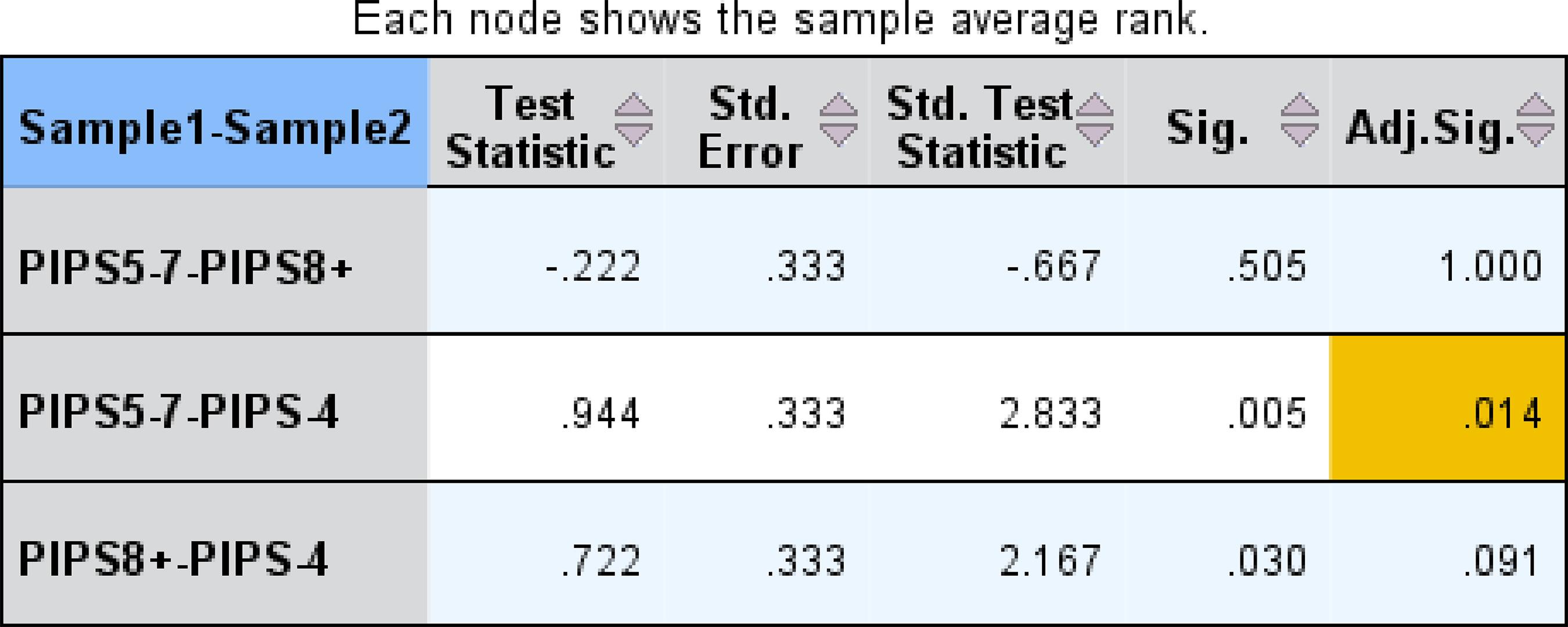
Na Figura 3, na relação par a par, obtida por meio da análise de variância pelo modelo de relações simples de Friedman, podemos observar, na comparação entre as leituras de pseudopalavras pelos participantes, que houve diferença estatisticamente significativa apenas entre o grupo de quatro grafemas ou menos e o de cinco a sete grafemas, com valor de p ajustado de 0,014.
De maneira geral, sem fazer essa avaliação por turmas, tratando os dados na totalidade da amostra deste estudo, podemos afirmar que a maior extensão das palavras/pseudopalavras não impactou o tempo de conversão grafofonêmica dos participantes avaliados.
4.5 Da avaliação de possível efeito da extensão das palavras por turma
Para comparação entre os resultados por turma, exportamos os dados para o SPSS e, como se pode ver na Tabela 8, quando realizada a comparação, o software considerou apenas os primeiros cinco participantes de cada grupo para fins de padronização do número de informantes, cujos resultados foram: 0,266 ms para a conversão de cada grafema para o 2º ano, 0,215 ms para o 3º ano e 0,192 ms para o 4º ano. Numa observação da tendência matemática dos dados, verificamos diminuição na média de conversão à medida que aumentava o ano escolar.
Tabela 8 Descrição estatística das médias em milésimos de segundo dos anos escolares.
| N | Média | Desvio padrão | Mínimo | Máximo | Percentis | |||
|---|---|---|---|---|---|---|---|---|
| 25th | 50th (median) | 75th | ||||||
| 2 médias | 5 | .266 | .058 | .209 | .341 | .209 | .265 | .323 |
| 3 médias | 5 | .215 | .036 | .189 | .278 | .193 | .200 | .245 |
| 4 médias | 5 | .192 | .019 | .169 | .221 | .177 | .187 | .209 |
Fonte: Autoria própria.
Em seguida, interessou-nos investigar, além da diferença matemática, uma possível diferença estatística entre os grupos. Para isso, fizemos novamente uso do teste de Friedman, já que é o teste indicado para tratamento de dados não paramétricos, pareados entre três grupos.
O valor de p observado foi de 0,041. Esse resultado mostra que houve diferença entre os grupos, ou seja, existiu diferença estatisticamente significativa entre as turmas. O ranking mostra que os leitores mais lentos foram os do 2º ano e os mais rápidos, os do 4º.
Diante desse resultado, quisemos saber entre quais grupos havia diferença. Assim, também utilizamos o teste de Friedman no SPSS, especificamente o modelo de relações simples de Friedman.
Ainda comparando as médias, e considerando cada uma das categorias de regularidade (palavras regulares, palavras irregulares e pseudopalavras) por turma, calcularam-se as médias. E, para investigar uma possível diferença entre os grupos, fizemos uso do teste de Friedman, indicado para tratamento de dados não paramétricos pareados entre três grupos (Tabela 9).
Tabela 9 Médias em milésimos de segundo da categoria regularidade e valor de p da diferença entre as turmas.
| Médias de conversão | Diferença Valor de p |
|||
|---|---|---|---|---|
| 2º ano | 3º ano | 4º ano | ||
| Palavras regulares | 0,230 | 0,197 | 0,177 | 0,247 |
| Palavras irregulares | 0,263 | 0,214 | 0,189 | 0,165 |
| Pseudopalavras | 0,305 | 0,234 | 0,217 | 0,074 |
Fonte: Autoria própria.
Como é possível ver na Tabela 9, as médias vão diminuindo sensivelmente à medida que aumenta o ano escolar. Observando as palavras regulares, os participantes do 2º ano converteram cada grafema em 0,230 milissegundos; os do 3º ano, em 0,197 milissegundos; e os do 4º ano, em 0,177 milissegundos. Observando as palavras irregulares, os participantes do 2º ano converteram cada grafema em 0,263 milissegundos; os do 3º ano, em 0,214 milissegundos; e os do 4º ano, em 0,189 milissegundos. Observando as pseudopalavras, os participantes do 2º ano converteram cada grafema em 0,305 milissegundos; os do 3º ano, em 0,234 milissegundos; e os do 4º ano, em 0,217 milissegundos.
Em outras palavras, em todas as categorias de regularidade, os escolares com leitura mais lenta foram os do 2º ano, e os que fizeram a conversão grafofonêmica mais rápida foram os do 4º ano.
Apesar de a diferença, ao se avaliar os números absolutos, ser facilmente constatável, o valor de p resultante do teste de Friedman não atestou haver diferença estatisticamente significativa, provavelmente pelo reduzido número de participantes de cada grupo (N = 5).
4.6 Confrontando os resultados observados com estudos documentados
Em geral, os estudos documentados avaliam o efeito de extensão na velocidade e na precisão de conversão – essa última também chamada de “acurácia”. Neste estudo, concentramos nossa avaliação na velocidade de conversão, a que chamamos aqui de “taxa de conversão grafofonêmica”.
De acordo com Soares (2016), o efeito de extensão revela-se principalmente no início do aprendizado da leitura e da escrita e ocorre quando o número de letras contidas na palavra é grande, conduzindo a criança a uma leitura mais lenta e mais suscetível a erros. O efeito de extensão pode ser explicado pelo uso preferencial da rota fonológica, que, como concluem pesquisas com crianças brasileiras, manifesta-se, sobretudo, no início da aprendizagem da língua escrita, fase em que quanto maior o número de letras contidas na palavra, mais lenta e menos precisa é a leitura (Pinheiro, 1994, 2008).
Diversos estudos em Língua Portuguesa confirmam, de maneira geral, os postulados do modelo de dupla rota da leitura, ou seja, as crianças falantes do português parecem utilizar preferencialmente a estratégia fonológica no início da aprendizagem da leitura, estratégia que vai sendo gradualmente substituída pelo uso prioritário da estratégia lexical.
Considerando particularmente a variável tempo de conversão na direção grafema-fonema, observamos, na análise geral dos dados, que não houve efeito de extensão na leitura de palavras isoladas e pseudopalavras por nossos participantes. Na busca por explicações para esses achados, os quais, em princípio, não condizem com a literatura sobre o efeito de extensão na leitura oral, fomos levados a comparar a população avaliada. Diferentemente da maioria dos estudos documentados, que avaliam escolares na educação infantil e no início do processo de alfabetização, o nosso estudo contemplou escolares do 2º ao 4º anos, ou seja, crianças numa faixa etária em que o processo de aquisição e aprendizagem da leitura encontra-se em fase de maior consolidação. Em outras palavras, no comportamento leitor dos escolares avaliados, há o predomínio da leitura lexical, em detrimento da fonológica, o que pode estar na origem dos nossos achados.
Diversos estudos (Pinheiro, 1995, 2006; Salles e Parente, 2002; Sucena e Castro, 2005) sugerem que a leitura fonológica (rota fonológica) predomina no início da alfabetização e, à medida que o indivíduo avança no processo de escolarização, tende a migrar para a leitura lexical (rota lexical) – a primeira, um processo ascendente, de decodificação fonológica; e a última, um processo de acesso direto ao léxico mental. O fato de não termos observado em nossos participantes um efeito de extensão, pelo menos na variável avaliada aqui (a velocidade de conversão), pode ter decorrido da participação de escolares em processo adiantado de aprendizado da leitura e com predomínio da rota lexical, em detrimento da fonológica.
Diante desses achados, é possível conjecturarmos que o efeito de extensão da palavra afeta consideravelmente apenas o início da alfabetização (educação infantil e 1º ano do Ensino Fundamental I) e, em alguns indivíduos, o início do 2º ano. Conjecturamos, ainda, que entre o 3º e o 4º anos, quando as crianças estão desenvolvendo representações lexicais para os itens menos familiares (Pinheiro e Rothe-Neves, 2001), o efeito de extensão tende a ir desaparecendo.
Nossos participantes, leitores já autônomos – e, pela média de conversão constatada (Abreu e Guaresi, 2019 9), deduz-se que já apresentando níveis importantes de compreensão –, não foram afetados pela extensão da palavra, por conseguirem processar a leitura pela rota lexical. Nossos resultados sugerem, portanto, que o efeito de extensão não afeta de forma significativa leitores que não fazem uso preferencial da rota fonológica.
Apesar de ressalvas quanto ao nível de proficiência leitora, os nossos resultados não se coadunaram com os de estudo realizado por Sucena e Castro (2005) com crianças portuguesas, no qual o efeito de extensão foi observado na 2ª série, sendo avaliada a variável tempo de processamento de palavras e de não palavras – tendo o tempo sido maior entre essas últimas. Os autores concluíram que a conversão grafofonêmica das crianças era sensível às variáveis regularidade, extensão e complexidade. O mesmo estudo documentou que somente na 4ª série as crianças atingiam níveis mais elevados de correção (acurácia) na leitura de palavras irregulares e de não palavras com estrutura silábica mais complexa.
Para Coltheart e Rastle (1994), no início do processo de alfabetização, o comprimento da palavra afeta a leitura fonológica, a qual converte serialmente uma sequência de grafemas em fonemas, o que leva a um maior tempo de processamento na leitura de palavras grandes e aumenta as chances de erro nas palavras que apresentam grafemas com pronúncia arbitrária. Para os autores, em consonância com a conclusão a que chegamos em nosso estudo, de acordo com o modelo da dupla rota, a rota de fato mais afetada na conversão grafofonêmica é a fonológica, em detrimento da lexical.
Uma possível justificativa para esses achados discrepantes, a qual repousa no perfil dos participantes do nosso estudo, encontra respaldo no que foi documentado por Salles e Parente (2002, 2007) em pesquisas com crianças de 1º e 2º anos. Em suas investigações, os autores concluem que o efeito de extensão foi elevado principalmente na escrita, modalidade não avaliada em nosso estudo.
Apesar de não ser o objetivo estrito deste estudo, temos que registrar a recorrência – uma vez que pudemos observá-la em nossos resultados –, na categoria de palavras/pseudopalavras com oito grafemas ou mais, de valores maiores no desvio padrão e no indicador de intervalo entre valores mínimos e máximos, o que, a nosso ver, aponta maior titubeio ou maior dificuldade no processo de conversão grafofonêmica, embora isso não tenha impactado o aumento da média na variável tempo de conversão.
5 Considerações finais
A pesquisa em questão situa-se na Linguística, especificamente na subárea da aquisição da linguagem, mais estritamente no que se refere ao possível efeito da extensão das palavras na leitura oral. Os dados levantados foram analisados sob a perspectiva psicolinguística, particularmente no modelo da dupla rota.
Na avaliação de um possível efeito de extensão na estrita variável tempo de conversão, os resultados deste estudo mostram que a extensão das palavras não impactou o tempo médio de conversão grafofonêmica de cada grafema. Ou seja, apesar de termos observado indícios de efeito de extensão em outras variáveis, nossos participantes não demoraram mais para converter os grafemas das palavras extensas, quando comparadas às curtas, independentemente de seu nível de regularidade.
A justificativa para tal achado, a nosso ver, pode repousar no perfil de nossos participantes, já com avançado nível de aprendizado e promovendo a leitura mais pela rota lexical – em detrimento da rota fonológica, na qual, em geral, se observa mais facilmente o efeito de extensão documentado na literatura.
Com o avanço nas séries escolares, há normalmente a melhora da automaticidade do reconhecimento visual das palavras e, consequentemente, o desenvolvimento da fluência leitora, promovendo uma transição da rota fonológica, característica do início do processo de alfabetização, para a lexical, em que ocorre acesso direto ao léxico mental.
Infelizmente não encontramos, na literatura explorada, estudos com perfis de participantes com os quais pudéssemos comparar nossos resultados. Como próximo passo, esses resultados permitirão avaliar um possível efeito da extensão das palavras na acurácia da conversão grafofonêmica, bem como ensejarão novas pesquisas, com o delineamento deste estudo, para, ao mesmo tempo, ratificar esses achados e buscar leitores com perfil mais díspar, com o fim de avaliar se o efeito de extensão não se restringe a leitores iniciantes.